R Basics
This is just a sneak peek on forthcoming weeks. Here I’ll post the PT-BR version of the first pages of a R crash course that, hopefully, will help you out to start your career as a data scientist. Enjoy:
Native graph functions: Gráficos de funções nativas
Este capítulo apresentará algumas ferramentas nativas em R responsáveis pela exibição gráfica de alguns conjuntos de dados. Estatística descritiva e a escolha da maneira correta de apresentar os dados são de grande importância para um cientista de dados. Em outros capítulos, serão apresentadas outras maneiras de se criar exibições gráficas mais detalhadas e com outras opções, com pacotes que não são nativos do R.
Histogramas
O dataset trees traz informações sobre algumas árvores. Observando um resumo básico deste dataset, temos:
summary(trees)## Girth Height Volume
## Min. : 8.30 Min. :63 Min. :10.20
## 1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
## Median :12.90 Median :76 Median :24.20
## Mean :13.25 Mean :76 Mean :30.17
## 3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
## Max. :20.60 Max. :87 Max. :77.00A coluna Girth informa o calibre de um tronco, enquanto que Heightapresenta a altura da árvore. Por fim, Volume informa, provavelmente em metros cúbicos, a capacidade tridimensional de ocupação da madeira daquela árvore. Apresentaremos agora a representação do dataframe trees em forma de histograma:
#histograma da altura das ?rvores com 10 caixinhas de intervalo
histograma <- hist(trees$Height,breaks=10)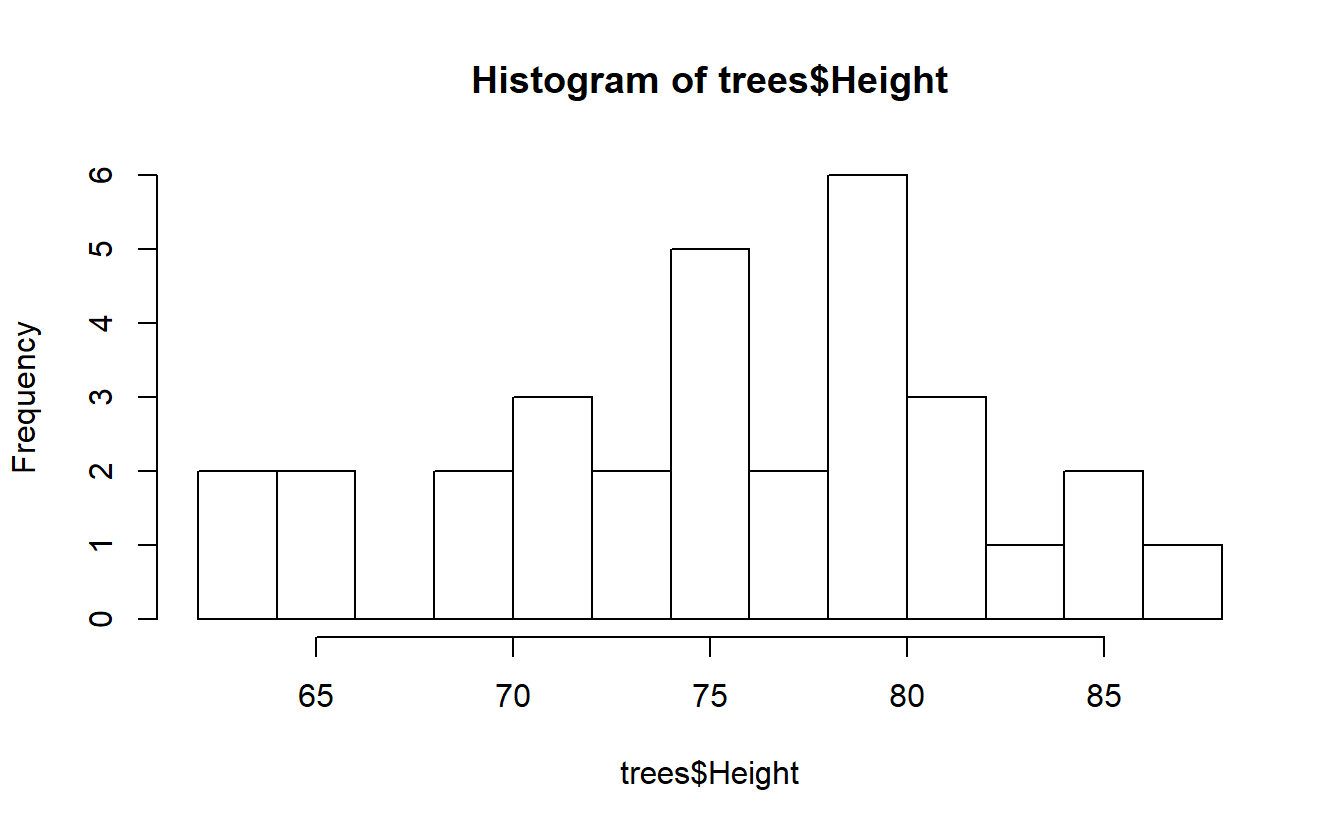
Esta visualização é muito simplificada e pode ser melhorada. Por exemplo, os componentes do histograma poderiam ser azuis e vazados, e os eixos poderiam trazer alguma informação significativa acerca das dimensões examinadas. Também é possível, como visto abaixo, criar um título para o gráfico:
#complementando a estética do histograma anterior
plot(histograma,col="blue",density=40,
main="Árvores", ylab="Frequência",xlab="Altura")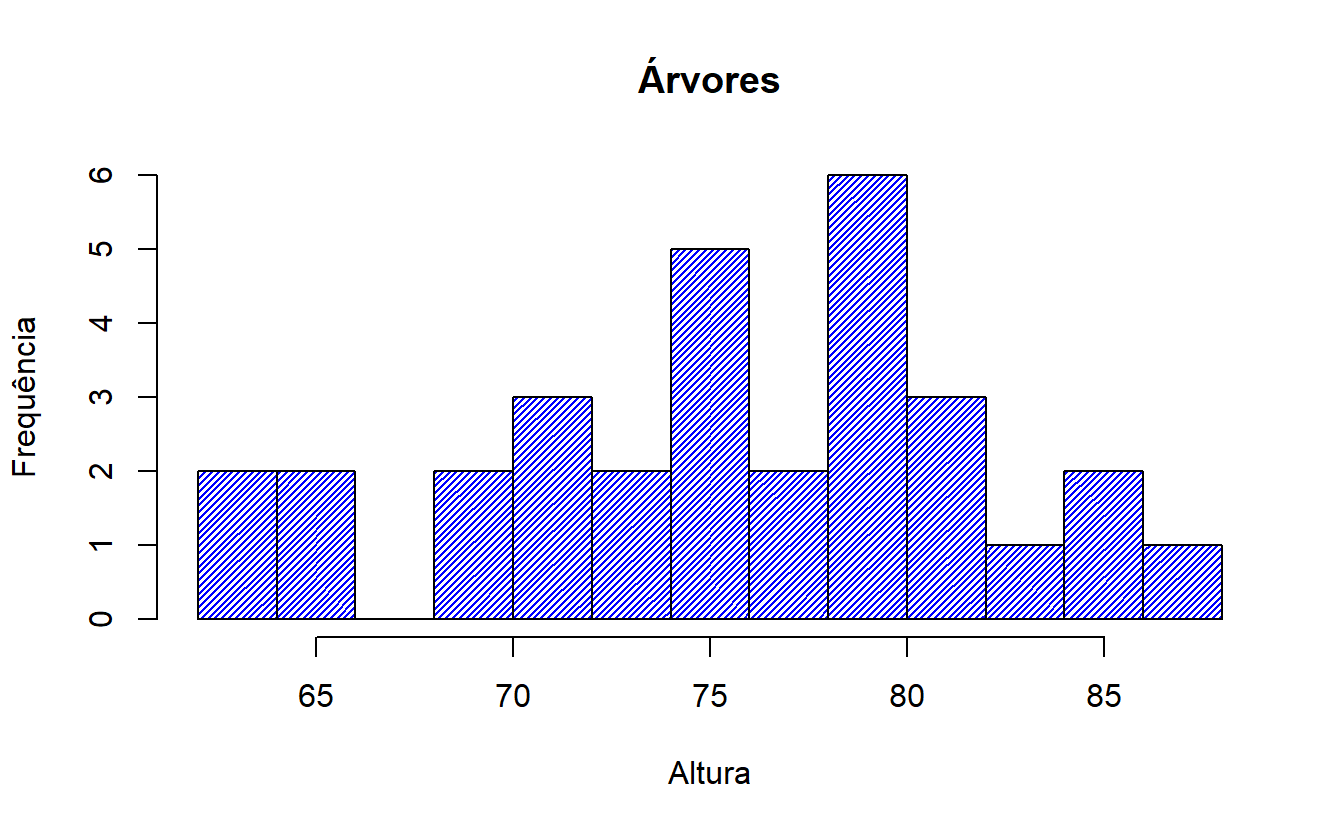
Densidade
Ainda tomando como base o exemplo anterior, é possível que se deseje conhecer a curva que descreve a distribuição de densidade das alturas das árvores no dataset. Isso é possível através da função density().
#densidade das alturas, representadas por uma linha azul
densidade <- density(trees$Height)
plot(densidade,col="blue")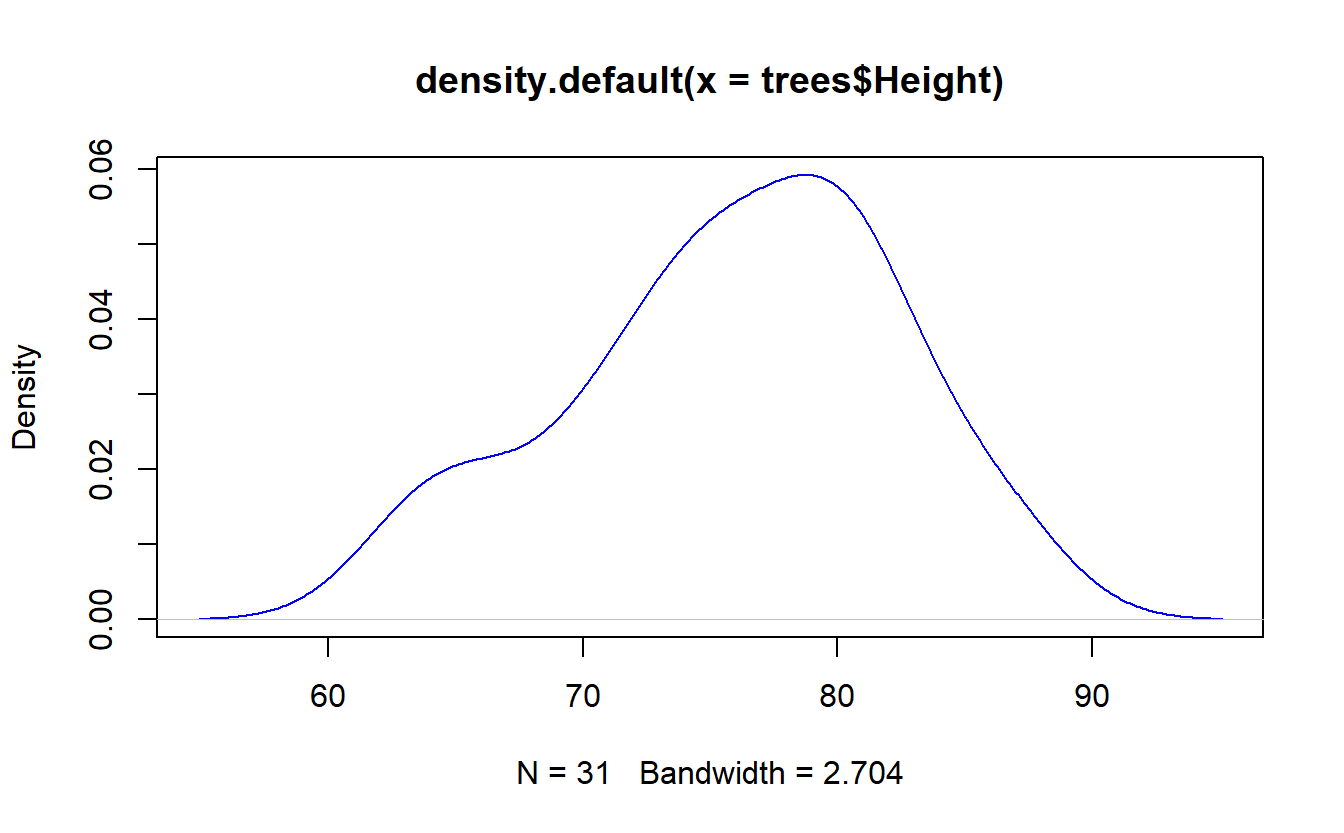
Sobreposição
Em uma situação em que seja necessário se comparar mais de uma representação, o recurso de sobreposição é indispensável. Tomemos como exemplo o caso anterior, que foi representado tanto em um gráfico de histograma quanto por um gráfico de densidade. Em R, é possível sobrepor as duas exibições utilizando a função par().
#sobreposição das informações (histograma como primeira camada)
plot(histograma,col="red",density=40,
main="Árvores", ylab="Frequência",xlab="Altura")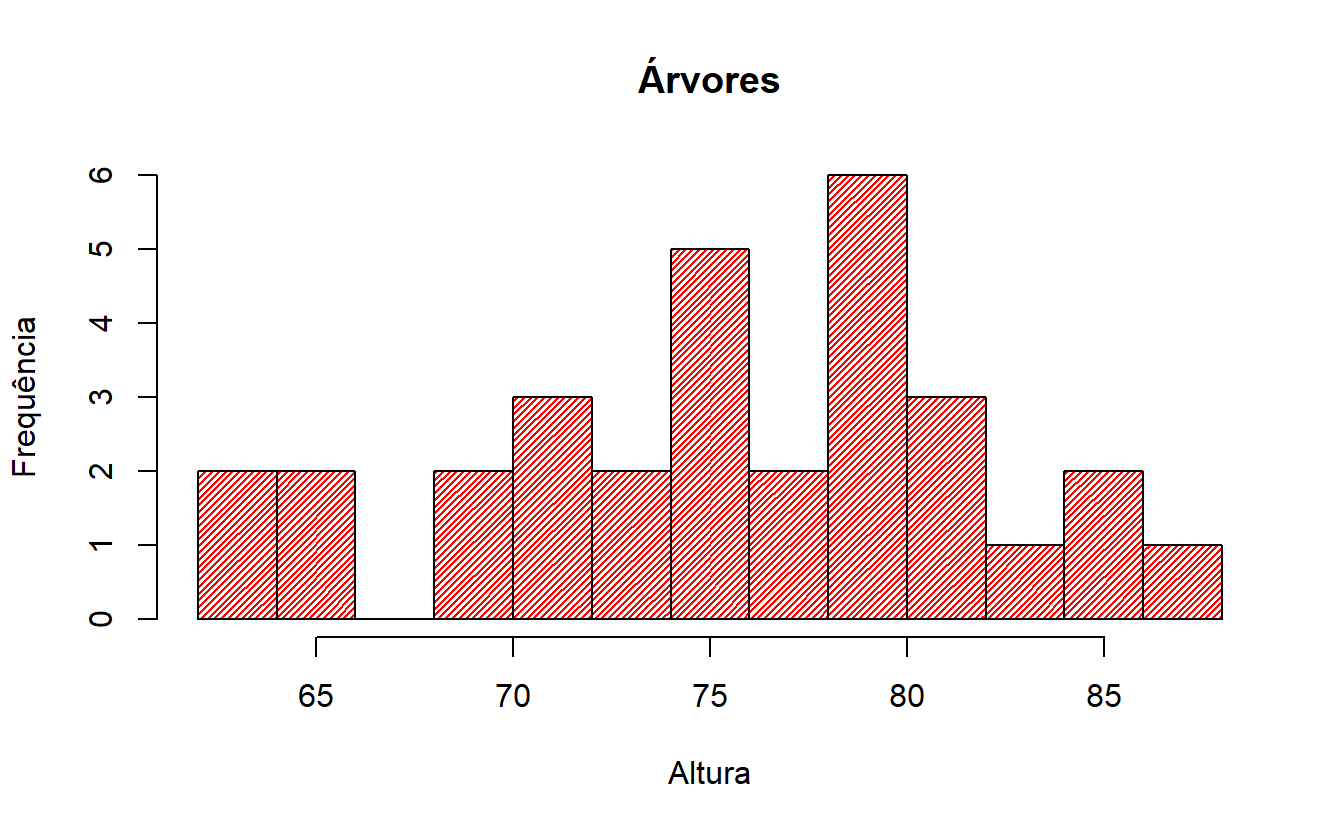
par(new=TRUE)#apagando as legendas e o título do gráfico de densidade
plot(densidade,col="blue",xaxt='n',yaxt='n',ann=FALSE)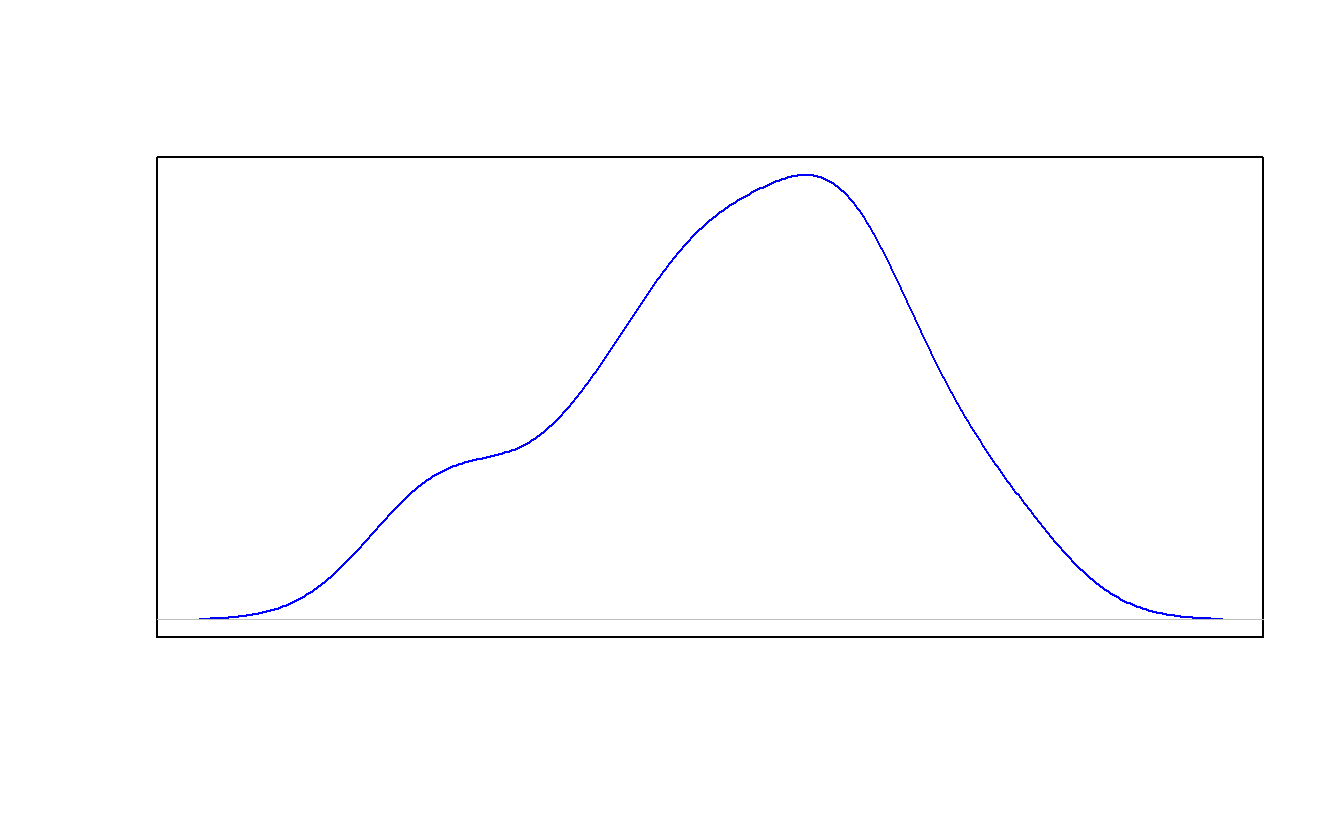
Gráfico de dispersão
O gráfico de pontos, ou dispersão, pode ser usado para melhor representar as observações em duas dimensões. Esse recurso permite enxergar possíveis tendências, correlações e a sua magnitude. No R, a função plot() pode exercer nativamente esse papel, juntamente com alguns argumentos extras:
#gráfico de dispersão do calibre das árvores versus volume
plot(trees$Girth,trees$Volume,
main="Árvores",ylab="circunferência",xlab="volume",col="blue",
pch=20)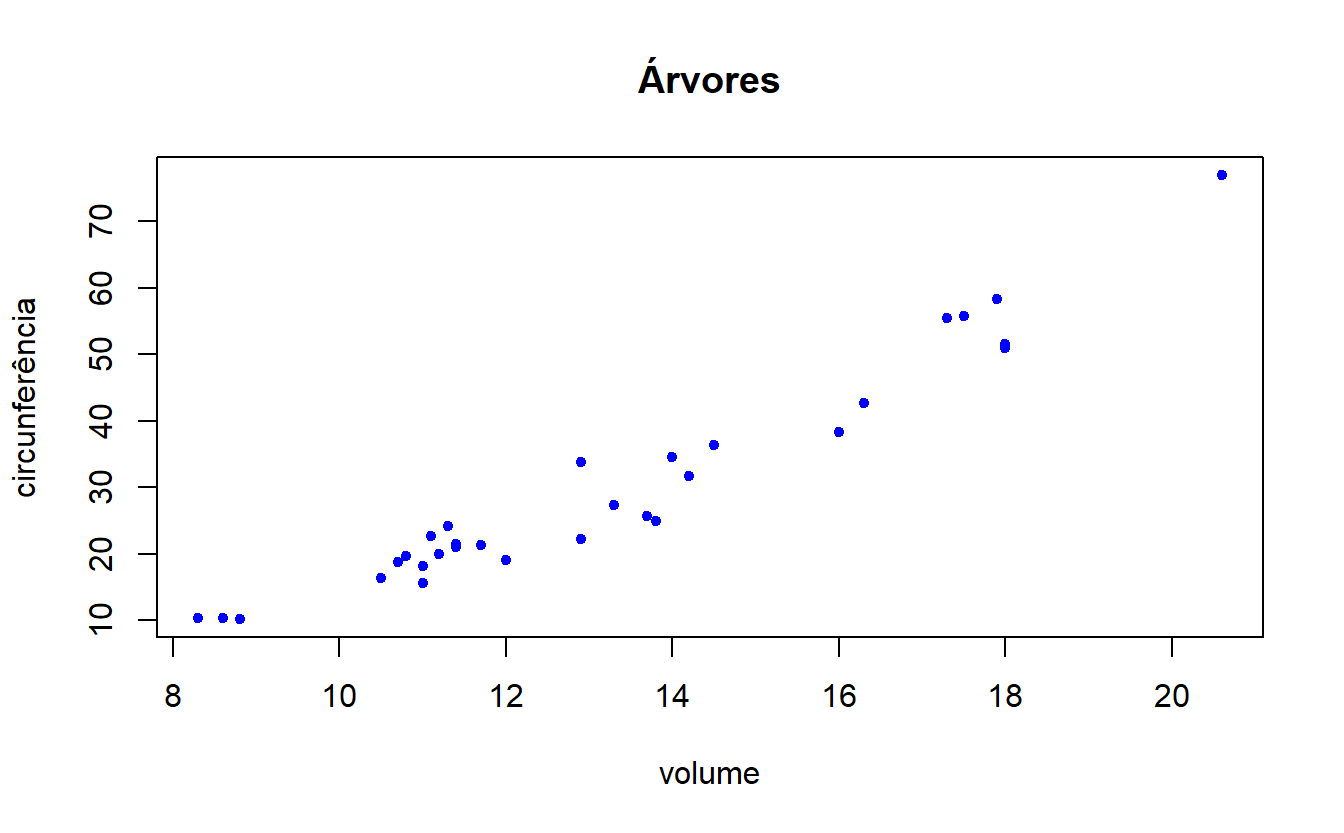
Para uma visão geral do dataset trees, o gráfico de dispersão também é muito útil, pois é possível enxergar a correlação de todas as variáveis com elas mesmas, em um grid amplo, utilizando a função plot() sem nenhum argumento, além do dataset em questão:
#plotando todas as correlações de todas as variáveis de uma só vez
plot(trees)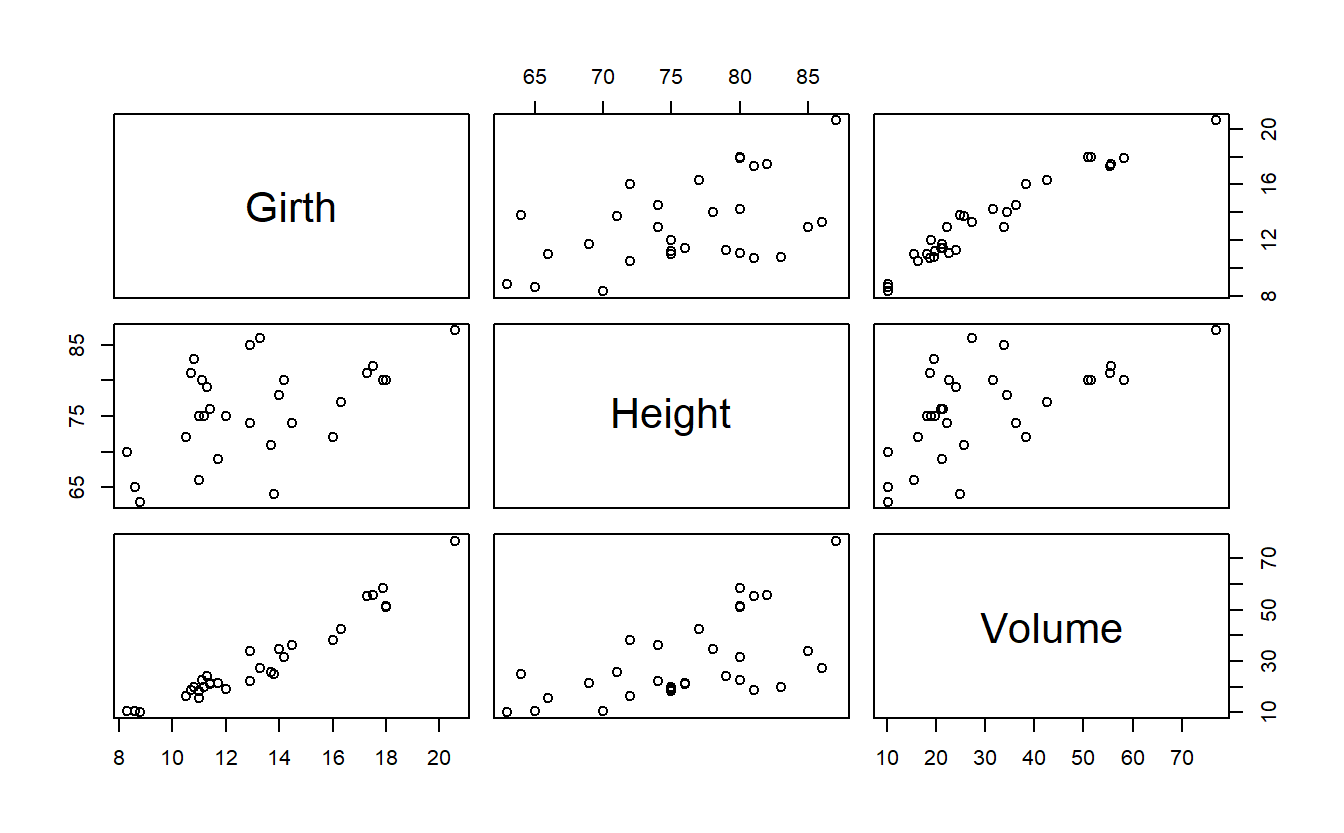
Também é possível dividir a tela em quantos espaços forem necessários, para uma exibição de diferentes tipos de gráficos:
#dividindo a tela para os gráficos que lhe interessam (nesse caso, dois)
split.screen(figs=c(1,2))## [1] 1 2#escolhendo o gráfico para a seção 1 da tela (nesse caso, o histograma)
screen(1)
plot(histograma)
#escolhendo o gráfico para a seção 2 da tela (nesse caso, gráfico de densidade)
screen(2)
plot(densidade)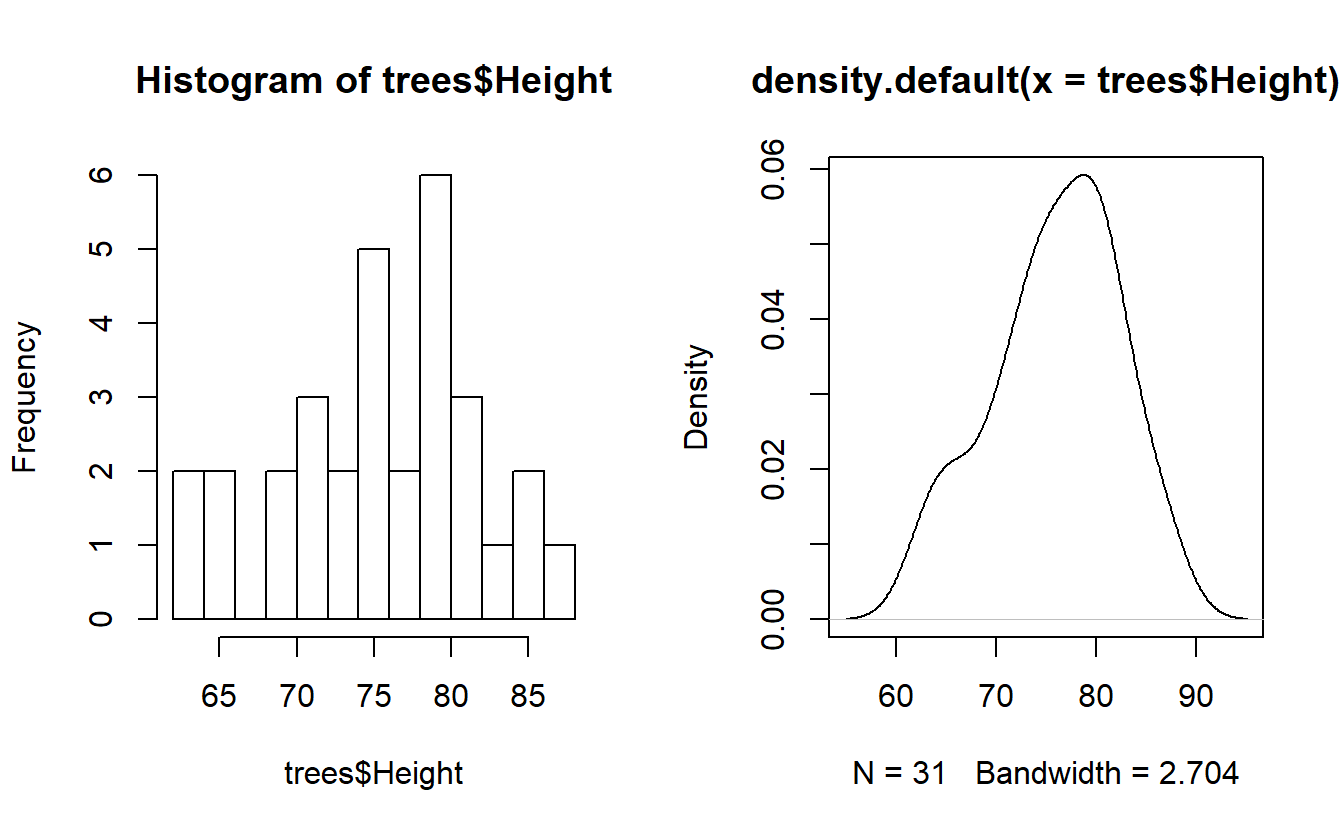
Boxplot
Uma outra representação de dados agregados muito utilizada é o boxplot. Com ele, é possível visualizar não apenas a distribuição dos dados, mas também a tendência de centralidade e a existência ou não de outliers no dataset.
#boxplot com visualizaÇão geral mais amigável de todo o conteúdo
boxplot(trees,horizontal=TRUE)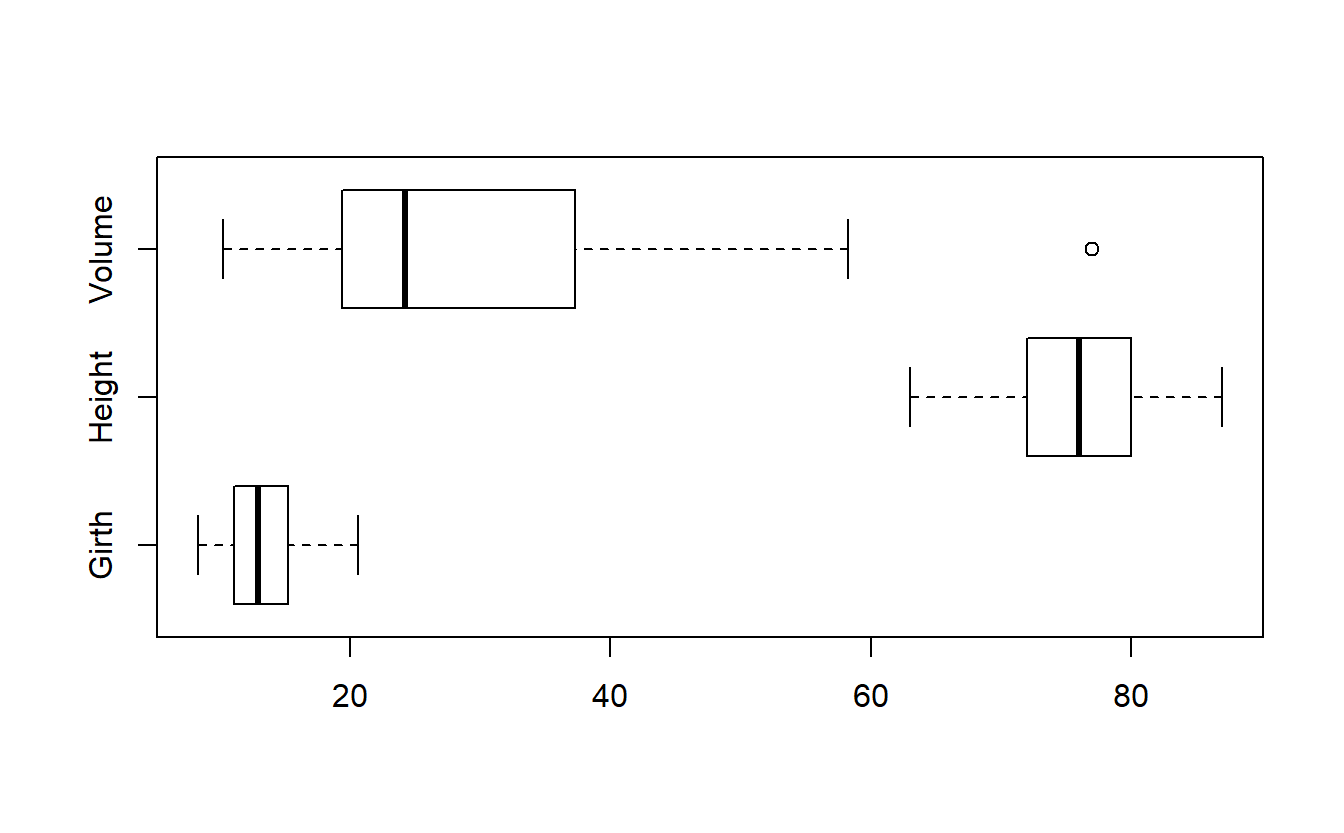
Gráfico de barras
Para a exibição em barras, é necessário que se agregue os dados de uma forma específica. Tomemos como exemplo o dataset pop, que pode ser visualizado de maneira geral abaixo:
#criação de um dataframe chamado pop
pop <- as.data.frame(matrix(c(13,45,9,17,17,21,"A","B","A","C","A","B"),
ncol=2,nrow=6))
colnames(pop) <- c("quantidade","cidade")
pop## quantidade cidade
## 1 13 A
## 2 45 B
## 3 9 A
## 4 17 C
## 5 17 A
## 6 21 B#gráfico de barras de habitantes por cidade (com agregação dos dados)
hab <- aggregate(. ~cidade,data=pop,sum) #criação do gráfico de barras e encapsulamento por box()
barplot(hab$quantidade,col=gray.colors(3),xlab="cidade",ylab="total",
names.arg=hab$cidade)
box()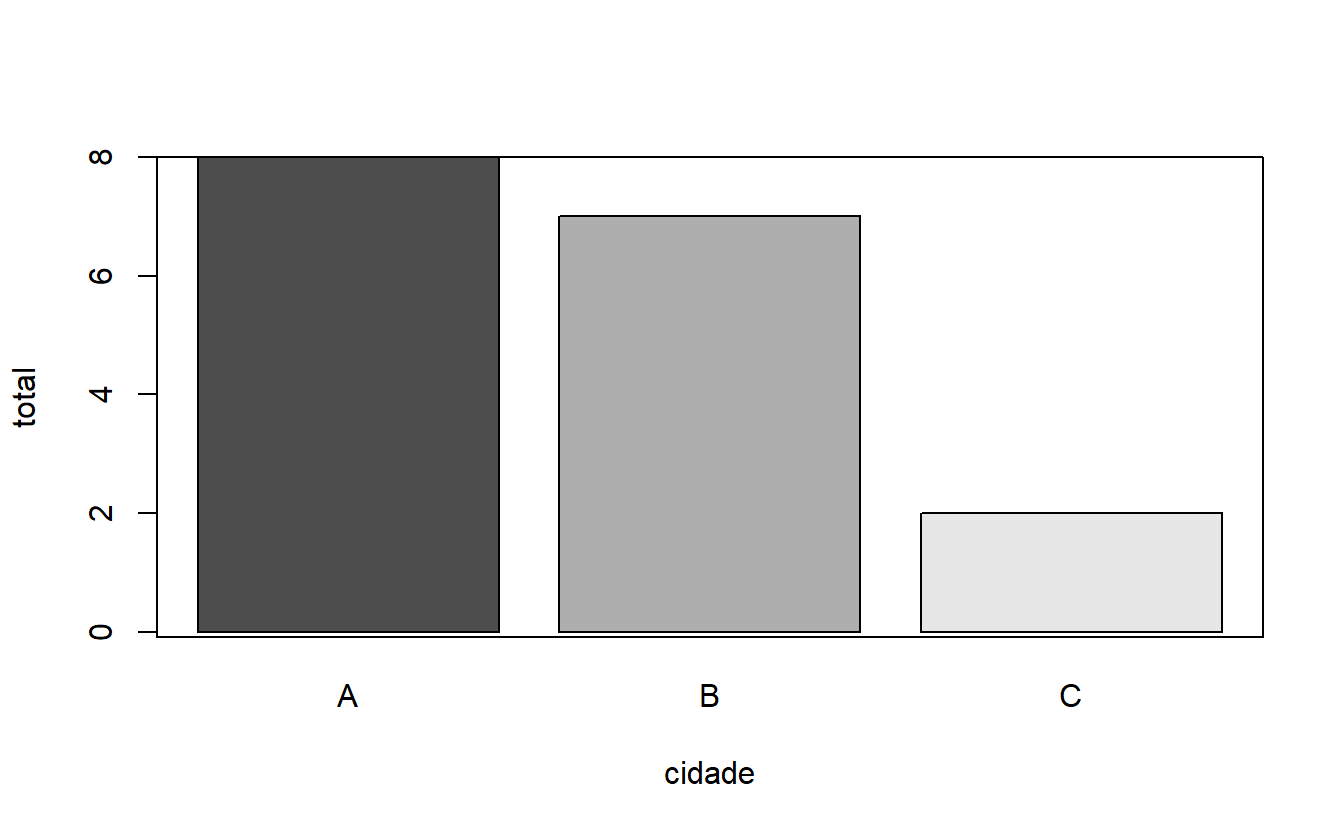
Gráfico de setores
Também conhecido informalmente como “gráfico de pizza”, pode ser facilmente plotado em R através da seguinte função, juntamente com uma legenda:
#gráfico de setores (usando os dados agregados)
pie(hab$quantidade,main="Cidades",col=c(4:6),labels=NA)
#legenda
legend("bottomright",legend=hab$cidade,cex=1,fill=c(4:6))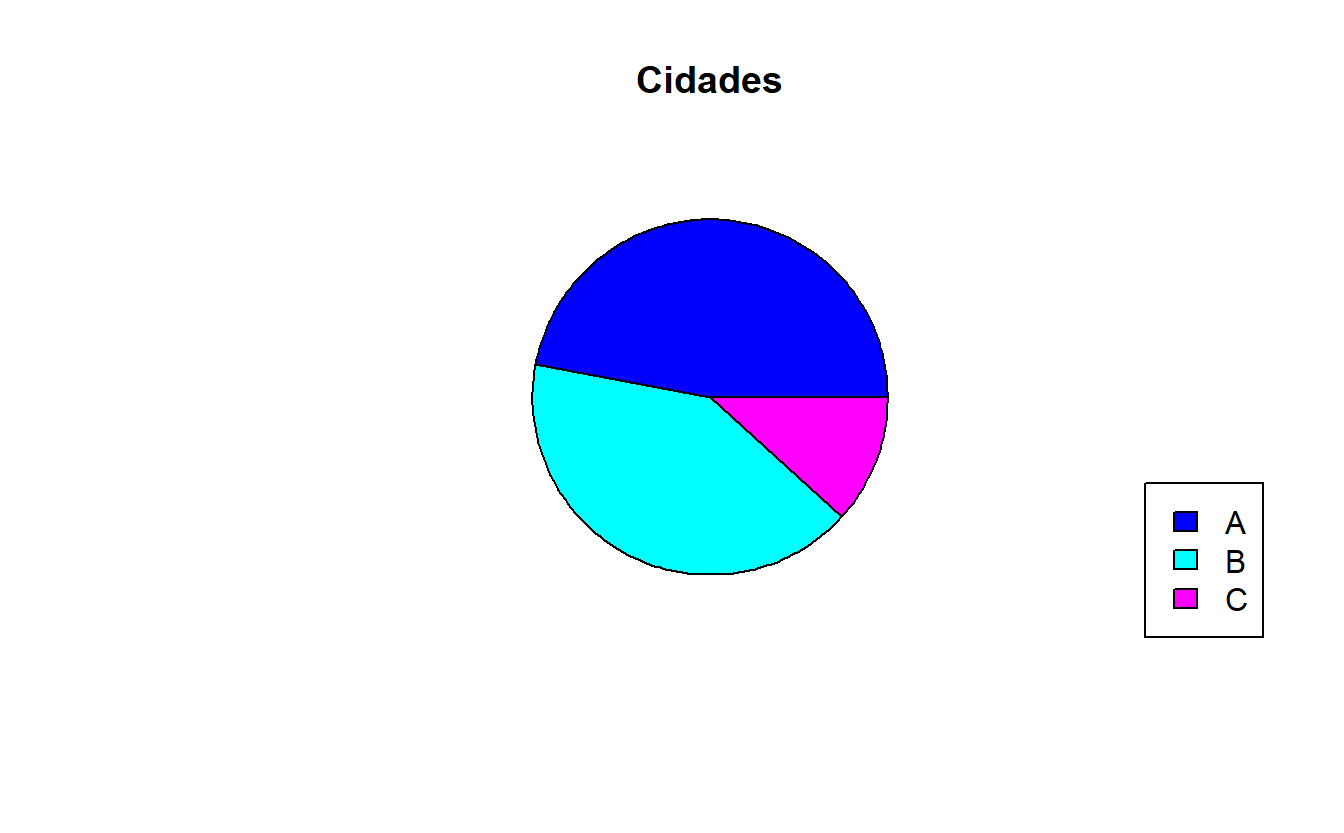
ggplot
As funções nativas do R são muito versáteis e conseguem cobrir muitas necessidades de um analista de dados. Contudo, há também uma abordagem diferente, através do pacote ggplot2. Este pacote pode ser facilmente encontrado, instalado e carregado:
install.packages("ggplot2")
library(ggplot2)A vantagem desse pacote é que ele possibilita a construção dos gráficos em sete diferentes camadas, com dependência entre elas: a segunda só pode ser construida se existir a primeira, a terceira só pode ser construida se existir a segunda, e assim por diante.
A primeira camada é responsável pelo conteúdo dos dados, enquanto que a segunda diz respeito à primeira etapa de visualização (escala) do gráfico. A terceira descreve a geometria de como os dados serão apresentados, ao passo que a quarta camada possibilita a visualização de várias facetas diferentes do mesmo dataset. A quinta camada possibilita a análise estatística, a sexta delimita as regiões relevantes das coordenadas do gráfico e, por fim, a sétima camada apresenta o tema geral do trabalho. Todas essas etapas poderão ser vistas nos exemplos seguintes.
Histograma
Utilizaremos o dataset nativo iris, que contém informações sobre flores.
#carregando a base de dados dentro de um dataframe
iris <- iris#resumo dos tipos de variáveis
str(iris)## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...#sumário das entradas na base de dados
summary(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## O ggplot2 funciona com a adição de funções responsáveis pelas camadas. Exibiremos agora informações simples sobre o tamanho das sépalas das flores em histograma.
#visualizando os dados das flores em 10 bins vermelhos
ggplot(data=iris,aes(x=Sepal.Length)) +
geom_histogram(color="black",fill="red",bins=10)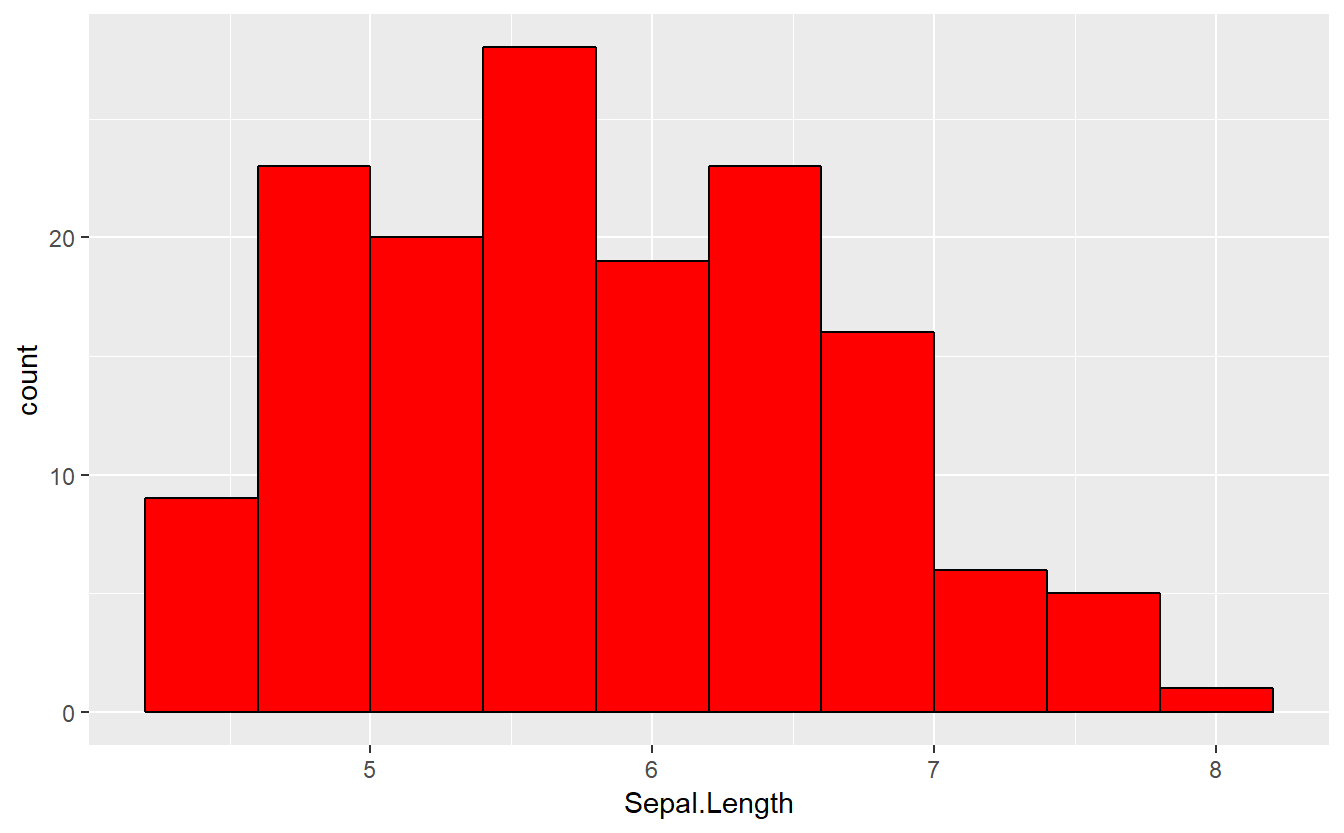
A função ggplot() indica ao R qual o dataset utilizado e qual trecho do dataset será plotado. A função geom_histogram() traz a informação de que será utilizado um histograma, e nesse exemplo os bins são de cor preta com preenchimento vermelho e a quantidade escolhida foi de 10.
Contudo, se houvesse a necessidade de se colorir cada um dos bins de acordo com a proporção da quantidade de espécies em cada m deles, as especificações podem ser ajustadas dentro da função aes(), dentro de ggplot().
ggplot(data=iris,aes(x=Sepal.Length,color=Species,fill=Species)) +
geom_histogram(color="black",bins=10)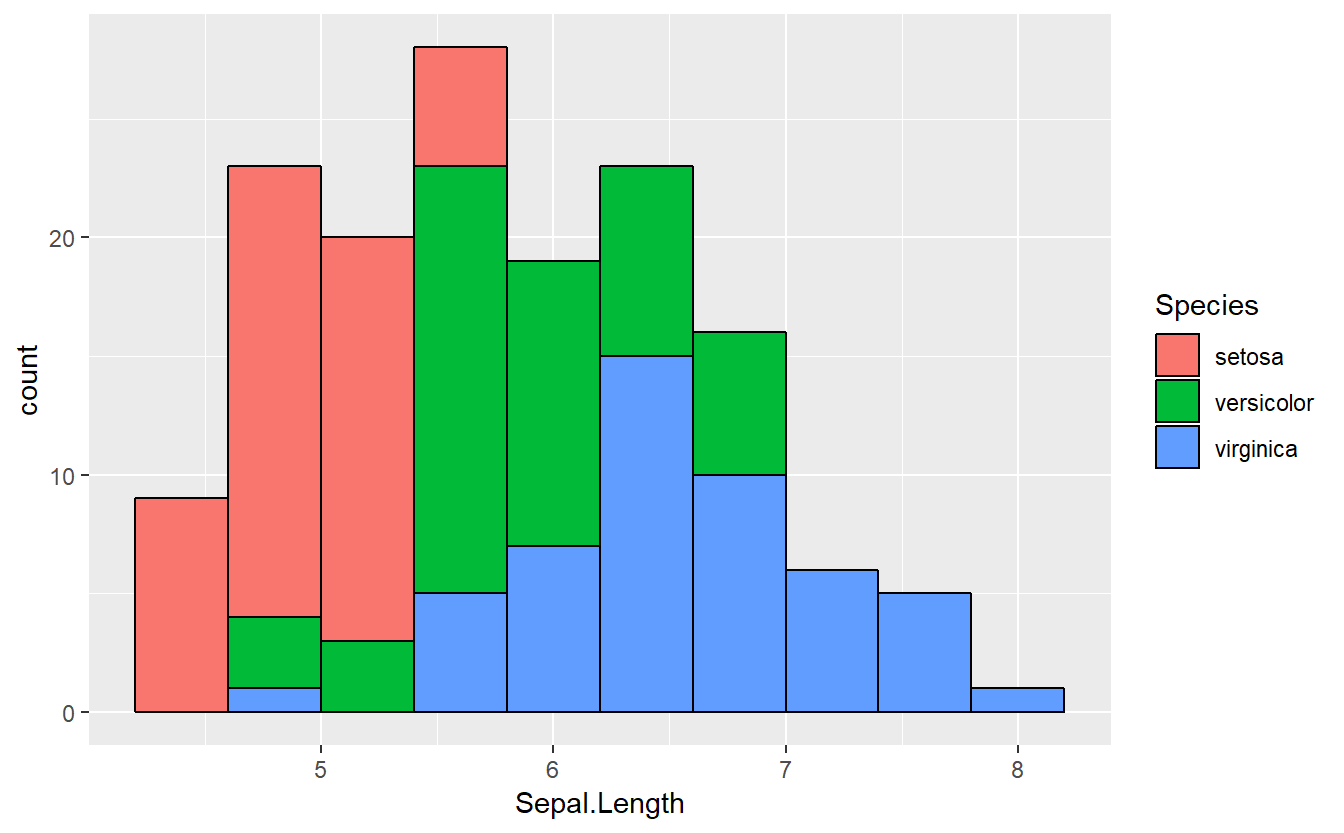
Densidade
Também é possível visualizar a distribuição de densidade dos dados através da função geom_density(). No exemplo seguinte, continuaremos a observar a distribuição de densidade do tamanho das sépalas, porém em uma distribuição de densidade por espécies, em curvas de contorno preto e preenchimento de 70% das cores relacionadas às espécies. Também é possível editar as legendas e os títulos do gráfico, com a função labs():
ggplot(data=iris,aes(x=Sepal.Length,color=Species,fill=Species)) +
geom_density(color="black", alpha = 0.7) +
labs(title="Curva de densidade",x="Tamanho das sépalas",y="Densidade")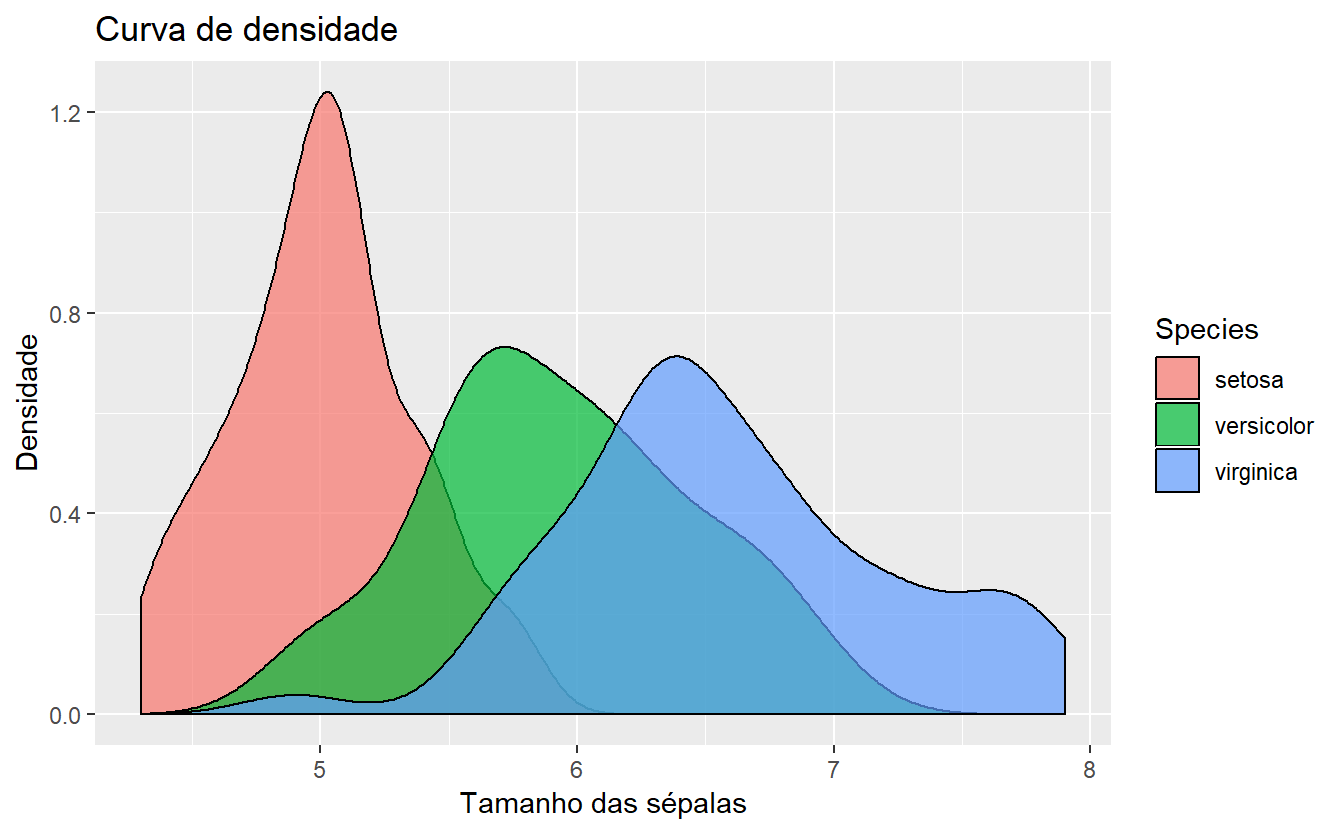
Gráfico de barras
Para a análise com gráfico de barras, utilizaremos a função geom_bar(). Exibiremos o dataset mpg, que contém dados referentes a vários tipos de carros.
mpg <- mpg
str(mpg)## Classes 'tbl_df', 'tbl' and 'data.frame': 234 obs. of 11 variables:
## $ manufacturer: chr "audi" "audi" "audi" "audi" ...
## $ model : chr "a4" "a4" "a4" "a4" ...
## $ displ : num 1.8 1.8 2 2 2.8 2.8 3.1 1.8 1.8 2 ...
## $ year : int 1999 1999 2008 2008 1999 1999 2008 1999 1999 2008 ...
## $ cyl : int 4 4 4 4 6 6 6 4 4 4 ...
## $ trans : chr "auto(l5)" "manual(m5)" "manual(m6)" "auto(av)" ...
## $ drv : chr "f" "f" "f" "f" ...
## $ cty : int 18 21 20 21 16 18 18 18 16 20 ...
## $ hwy : int 29 29 31 30 26 26 27 26 25 28 ...
## $ fl : chr "p" "p" "p" "p" ...
## $ class : chr "compact" "compact" "compact" "compact" ...summary(mpg)## manufacturer model displ year
## Length:234 Length:234 Min. :1.600 Min. :1999
## Class :character Class :character 1st Qu.:2.400 1st Qu.:1999
## Mode :character Mode :character Median :3.300 Median :2004
## Mean :3.472 Mean :2004
## 3rd Qu.:4.600 3rd Qu.:2008
## Max. :7.000 Max. :2008
## cyl trans drv cty
## Min. :4.000 Length:234 Length:234 Min. : 9.00
## 1st Qu.:4.000 Class :character Class :character 1st Qu.:14.00
## Median :6.000 Mode :character Mode :character Median :17.00
## Mean :5.889 Mean :16.86
## 3rd Qu.:8.000 3rd Qu.:19.00
## Max. :8.000 Max. :35.00
## hwy fl class
## Min. :12.00 Length:234 Length:234
## 1st Qu.:18.00 Class :character Class :character
## Median :24.00 Mode :character Mode :character
## Mean :23.44
## 3rd Qu.:27.00
## Max. :44.00Os argumentos dessa função para exibição de gráfico de barras fazem referência ao tipo de estatística exibida (que será tratado mais adiante) e ao contorno das barras. A função coord_flip() rotaciona em 90 graus a exibição das barras, para o eixo horizontal.
#gráfico de barras para MPG
ggplot(data=mpg,aes(x=class,color=class,fill=class)) +
geom_bar(color="black") + coord_flip()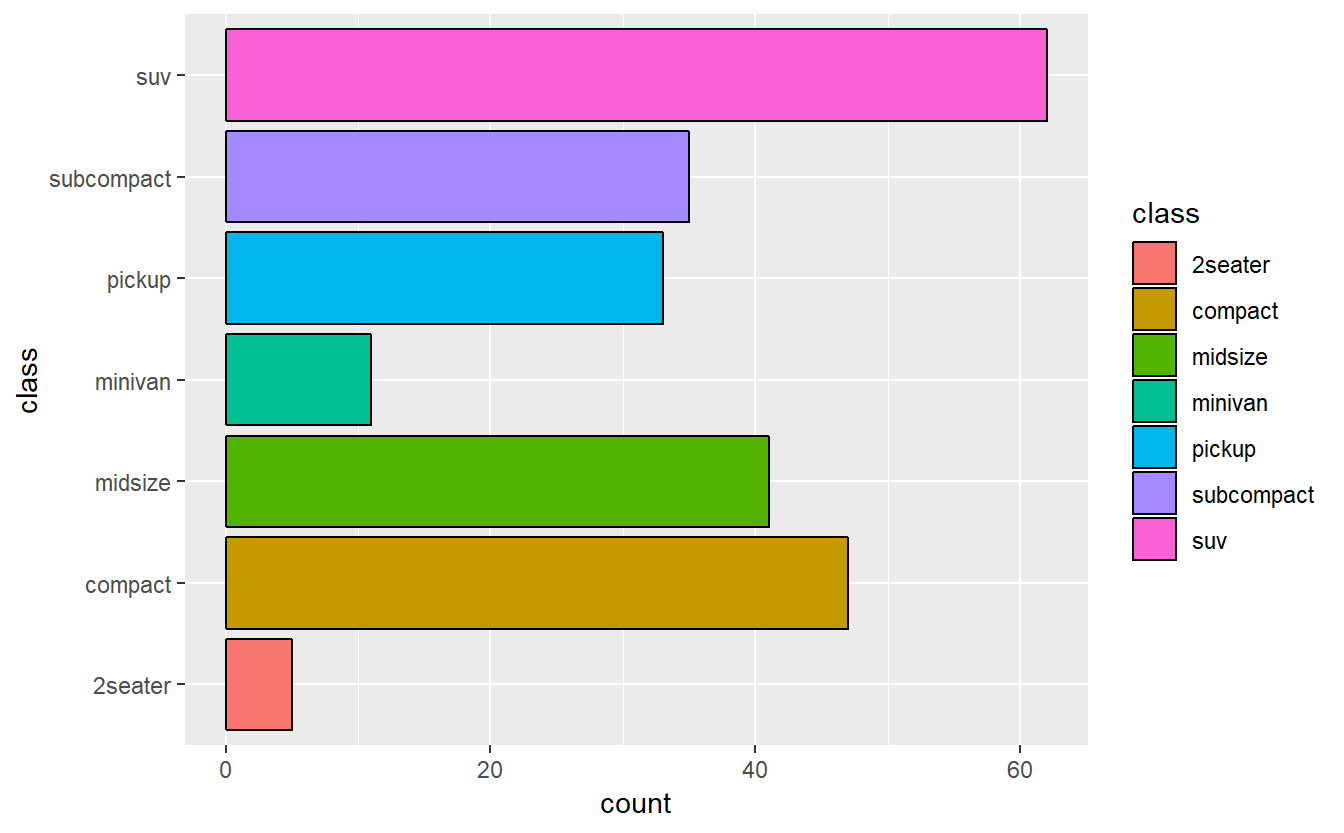
Para a exibição em gráfico de barras dos dados de acordo com uma variável categórica, é necessário primeiramente a criação de um dataframe novo, que será chamado de df. Nele, será armazendo o valor da média da grandeza displ (“disponibilidade”, em tradução livre) de cada um dos modelos de carros. Para tanto, será carregado o pacote tidyverse, explicado em outro capítulo em mais detalhes.
library(tidyverse)Com este pacote, é possível fazer uso não apenas de funções que auxiliam na criação de novas colunas e variáveis baseadas em valores já existentes, mas também do operador %>%, ou pipeline. A utilização deste operador é explicada em detalhes em outro capítulo.
#ordenando por uma variável categórica
df <- mpg %>% group_by(class) %>% dplyr::summarise(mean=mean(displ)) %>%
arrange(-mean) %>% mutate(class = factor(class,levels=class))No código, o dataframe df foi criado, tendo como base o dataframe anterior mpg. Agrupou-se por classe de carro através da função group_by() e aplicou-se a função summarise() do pacote dplyr (componente do tidyverse) na variável displ do dataset mpg. Mais especificamente, criou-se aí a variável mean responsável por trazer a informação da média de cada classe agrupada, através da função mean(). Em seguida, ordenou-se da menor para a maior com a função arrange() e o operador lógico -. Por fim, a função mutate()foi aplicada para a criação de mais uma variável no dataset df: a variável que continha os nomes dos tipos de carros ordenados pelos fatores da variável class do dataset mpg. O dataset pode ser visualizado a seguir:
df## # A tibble: 7 x 2
## class mean
## <fct> <dbl>
## 1 2seater 6.16
## 2 suv 4.46
## 3 pickup 4.42
## 4 minivan 3.39
## 5 midsize 2.92
## 6 subcompact 2.66
## 7 compact 2.33A partir desse ponto, é possível exibir os dados anteriores em um gráfico. O dataset será o df, no eixo X será exibido class e no eixo Y mean. As cores serão ajustadas de acordo com as classes de carro, tal como o preenchimento. A partir disso, os argumentos da função geom_bar() dizem respeito à natureza estatística da exibição e da cor do contorno das barras. Também será adicionado uma função para o título do eixo X e outra para o eixo Y. Por fim, a função geom_text() será responsável pelo ajuste estético da quantidade de casas decimais exibidas, da altura dos valores dentro de cada barra, da cor do texto, exibição de negrito e tamanho da fonte.
#exibindo a etapa anterior em gráfico
ggplot(data=df,aes(x=class,y=mean,color=class,fill=class)) +
geom_bar(stat="identity",color="black") + xlab("classe") + ylab("media") +
geom_text(aes(label=sprintf("%0.2f",round(mean,digits=2))),
vjust=1.6,color="white",fontface="bold",size=4) 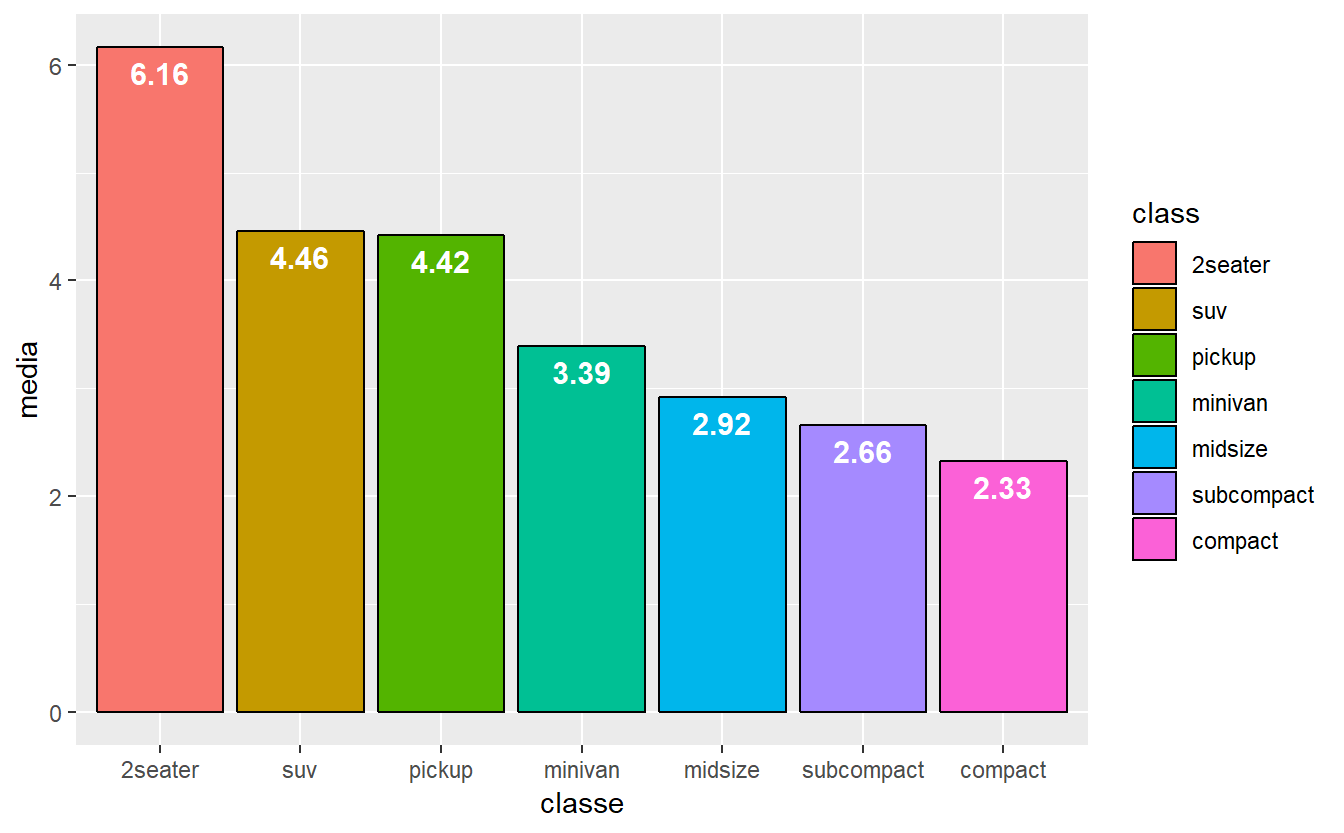
Também é possível exibir o gráfico de barras empilhado ou lado a lado por classes.
#exibindo gráfico de barras empilhados por classe, pelo tipo de tração
ggplot(data=mpg,aes(x=class,y=displ,fill=drv)) +
geom_bar(stat="identity")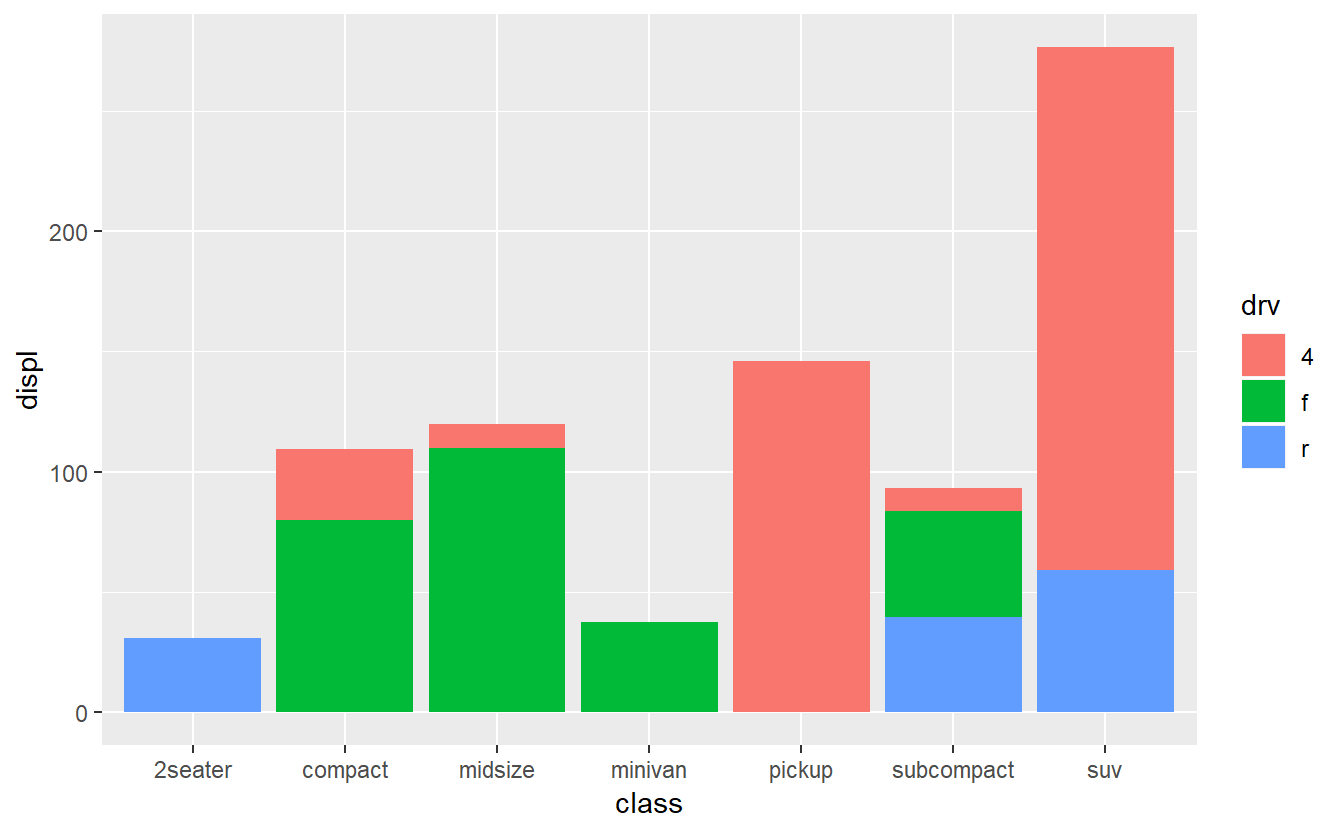
#exibindo gráfico de barras lado a lado por classe, pelo tipo de tração
ggplot(data=mpg,aes(x=class,y=displ,fill=drv)) +
geom_bar(stat="identity", position=position_dodge())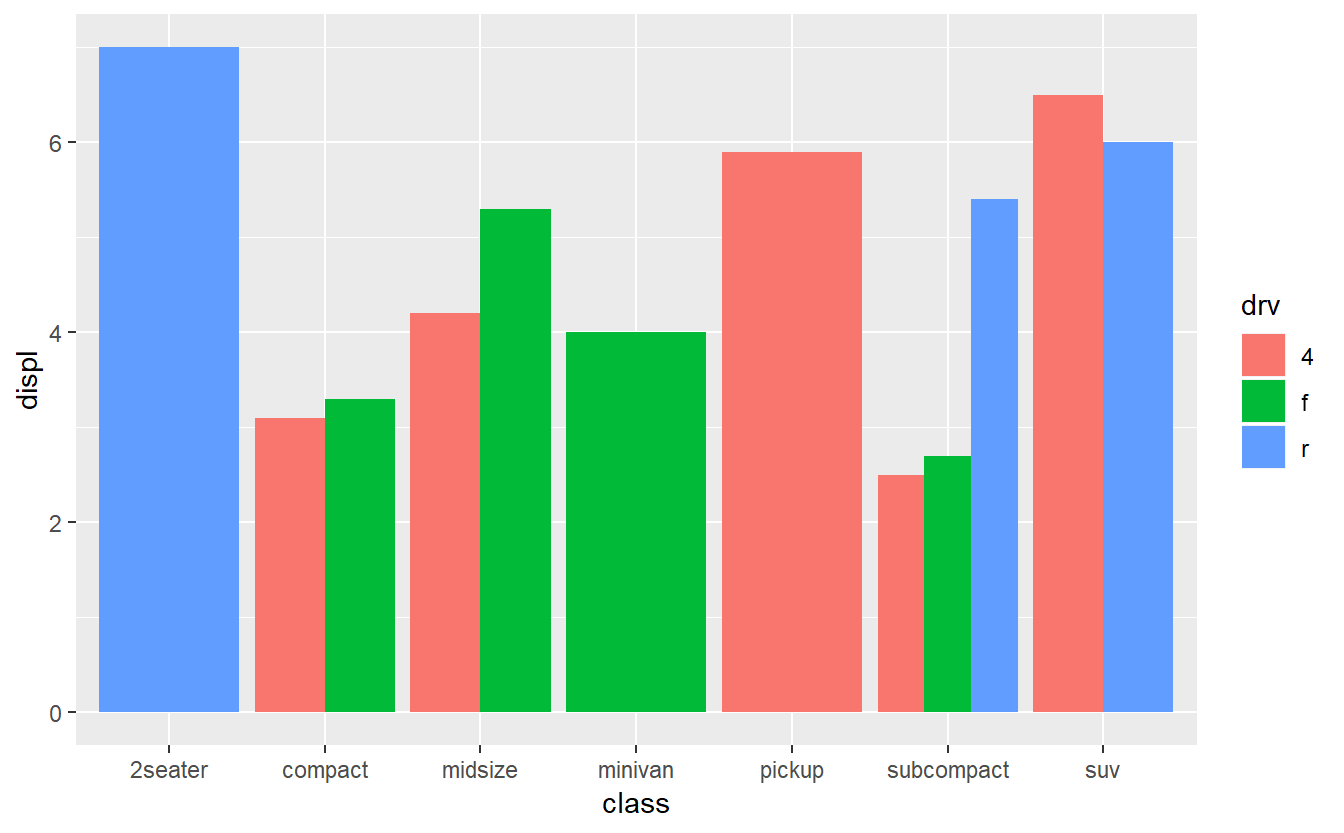
Boxplot
A exibição de dados em forma de boxplot segue a mesma lógica das exibições anteriores de histograma e de gráfico de barras: Utiliza-se primeiramente o ggplot() para a definição das primeiras camadas e a função geom_boxplot() para a escolha do tipo de gráfico. Para o dataset nativo mtcars temos:
mtcars <- mtcars
str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...summary(mtcars)## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000Exibindo a variável de fatores cyl no eixo X e a variável disp no eixo Y, com coloração para cada uma das classes de cilindradas, temos:
#boxplot das cilindradas dos carros
mtcars$cyl = factor(mtcars$cyl)
ggplot(data=mtcars, aes(x=cyl, y=disp,fill=cyl)) + geom_boxplot() +
xlab("cilindradas") + ylab("disponibilidade")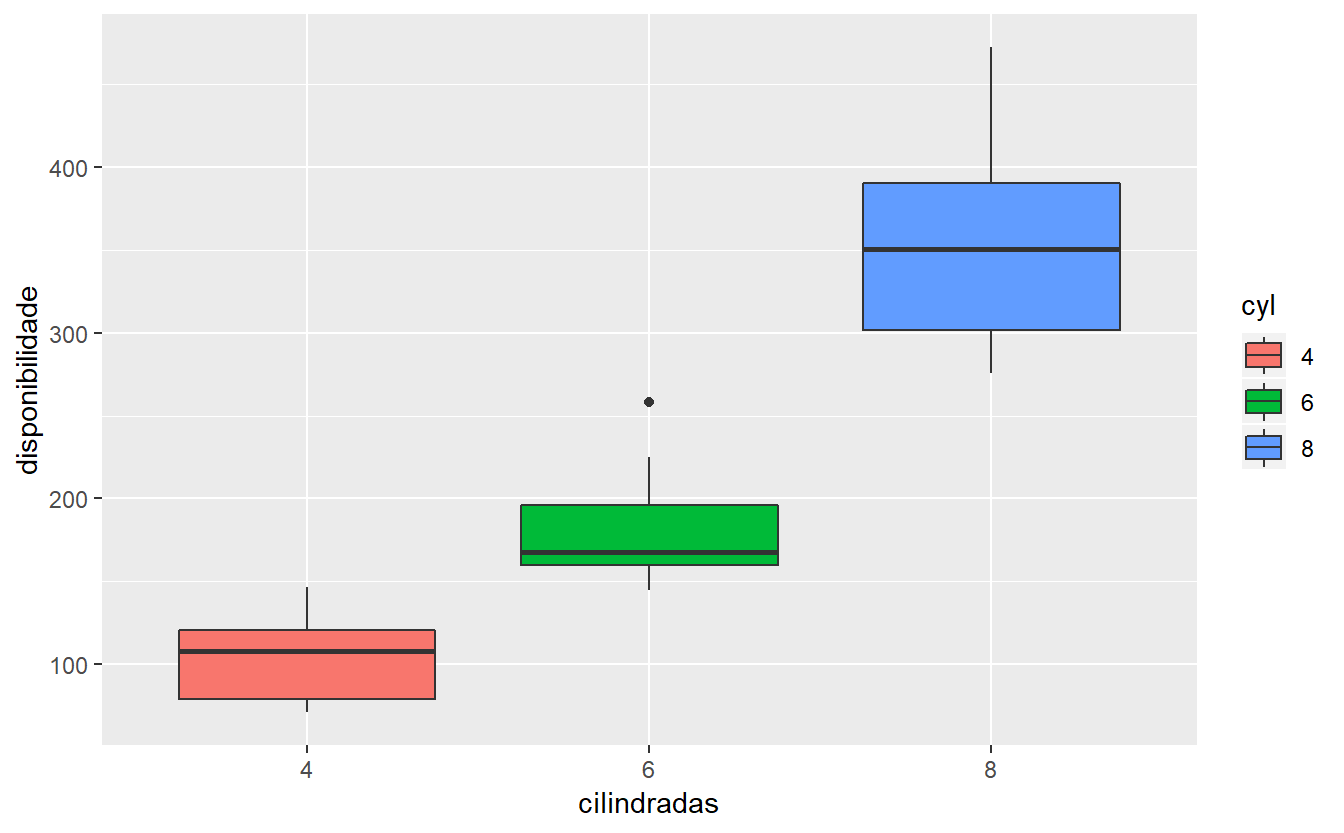
Gráfico de pontos
Utilizaremos a base de dados iris para a exibição do gráfico de pontos. Este tipo de gráfico é mais utilizado quando há uma quantidade consideravelmente grande de dados e deseja-se saber se há uma correlação (e sua intensidade) entre as variáveis. No pacote ggplot, os gráficos de pontos estão disponíveis através da função geom_point().
#gráfico de pontos da tamanho da sépala (eixo x) pela largura da sépala (eixo y)
ggplot(data=iris,aes(x=Sepal.Length,y=Sepal.Width,shape=Species,color=Species)) +
geom_point() + xlab("Altura") + ylab("Largura")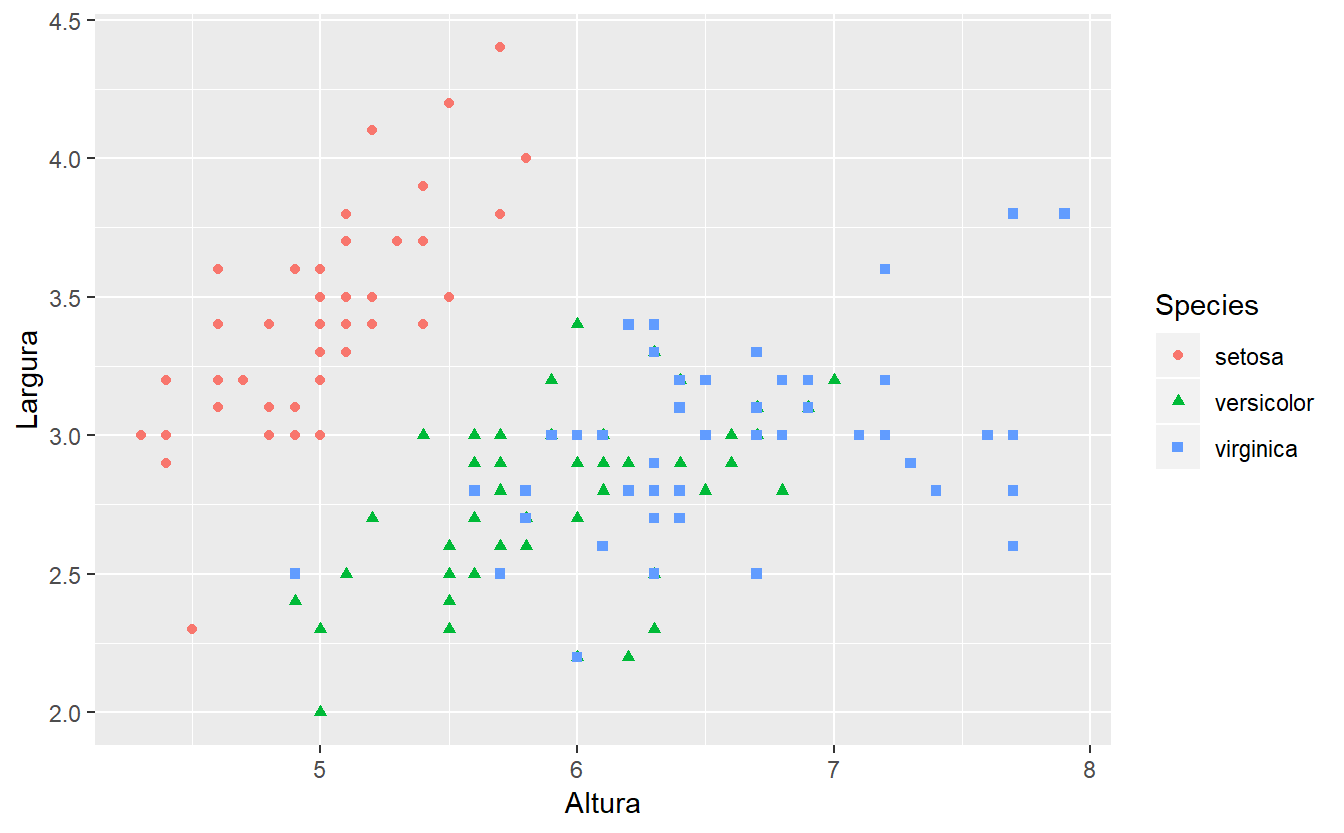
Para o dataset de carros:
#gráfico de pontos de uma parte específica dos carros das cilindradas
ggplot(data=subset(mtcars,am==0),aes(x=mpg,y=disp,color=cyl)) + geom_point()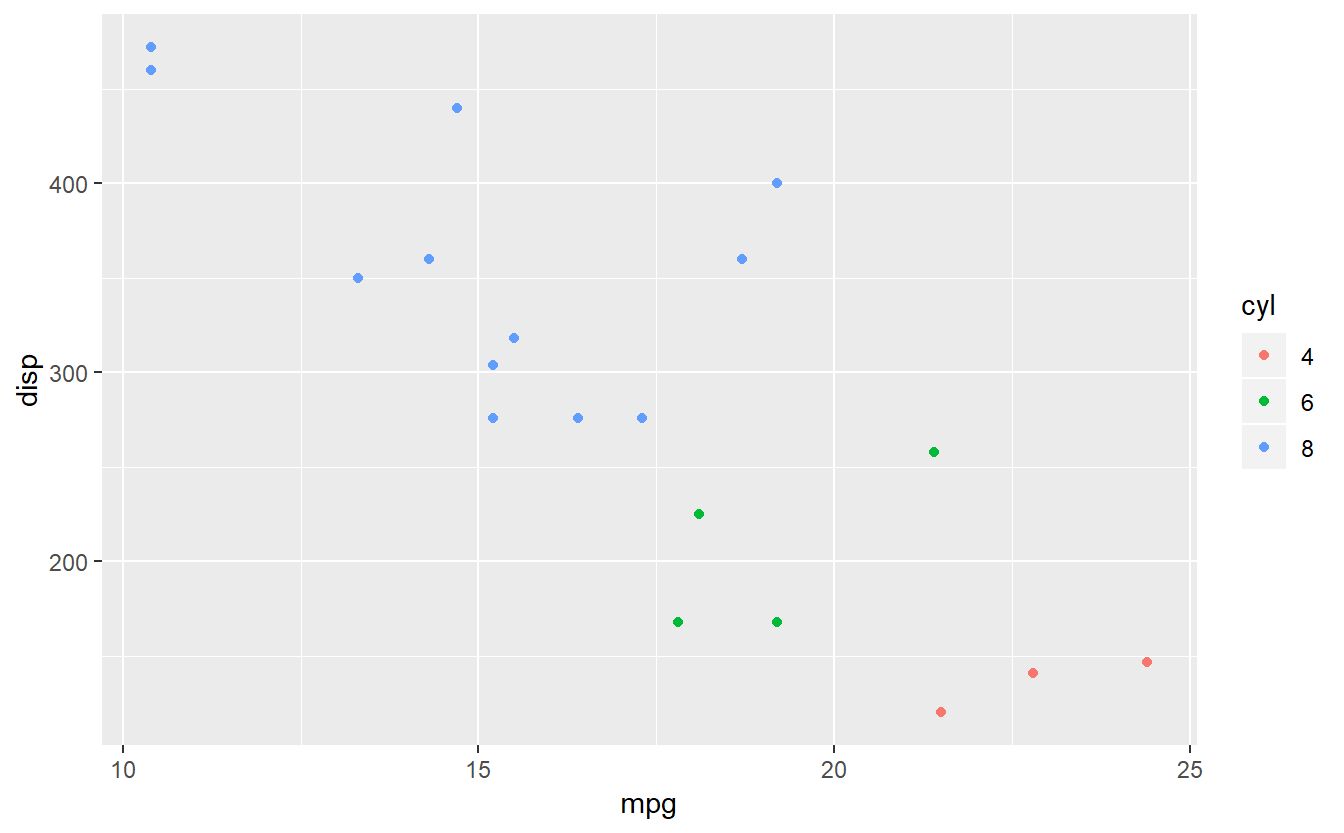
Também é possível armazenar uma parte do plot em uma lista e criar variações sobre ela. Como exemplo, o gráfico de pontos com curva suavizada no dataset de carros, dentro da lista grafico:
#gráfico de pontos suavizado e com linha de acompanhamento dos cavalo-vapor
grafico <- ggplot(data = mtcars, aes(x = mpg,y = disp, color = hp)) + geom_point(size=2.5) +
geom_smooth() + geom_line(aes(y=hp))
grafico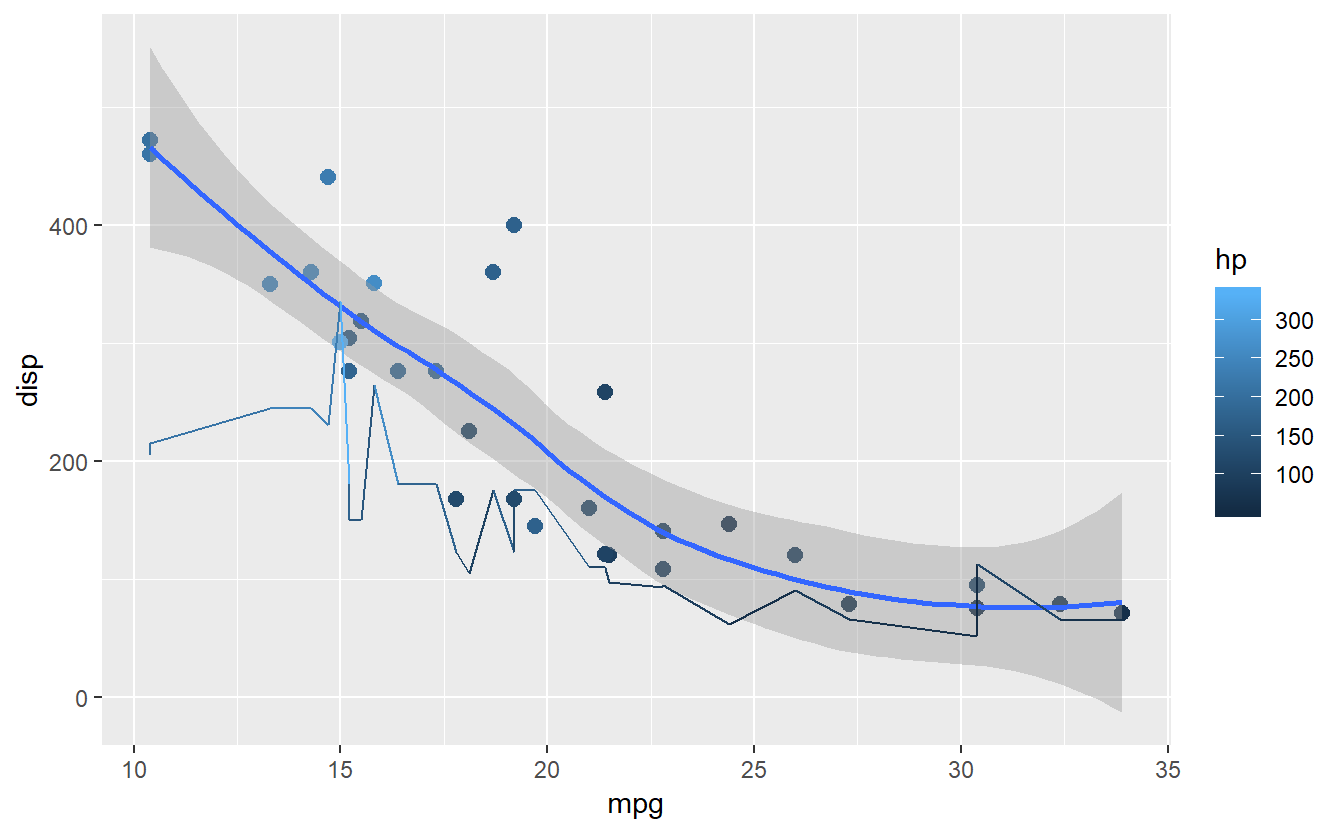
#mesma coisa do anterior, só que com tema cinzento
grafico + labs(title="Gráfico") +
theme(plot.title=element_text(color="blue",size=17),
plot.background=element_rect("grey"))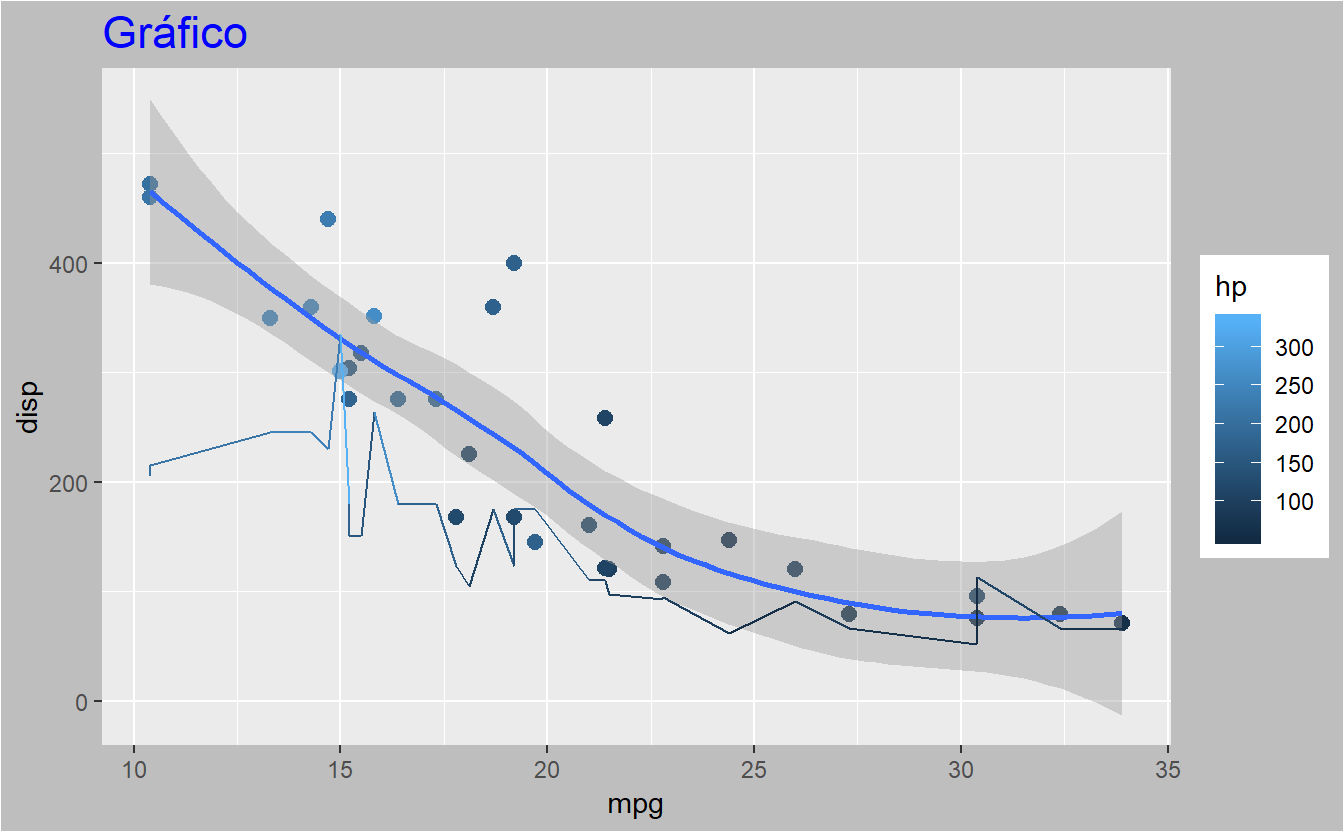
#mesma coisa do anterior, só que com um tema pré-pronto
grafico + theme_dark()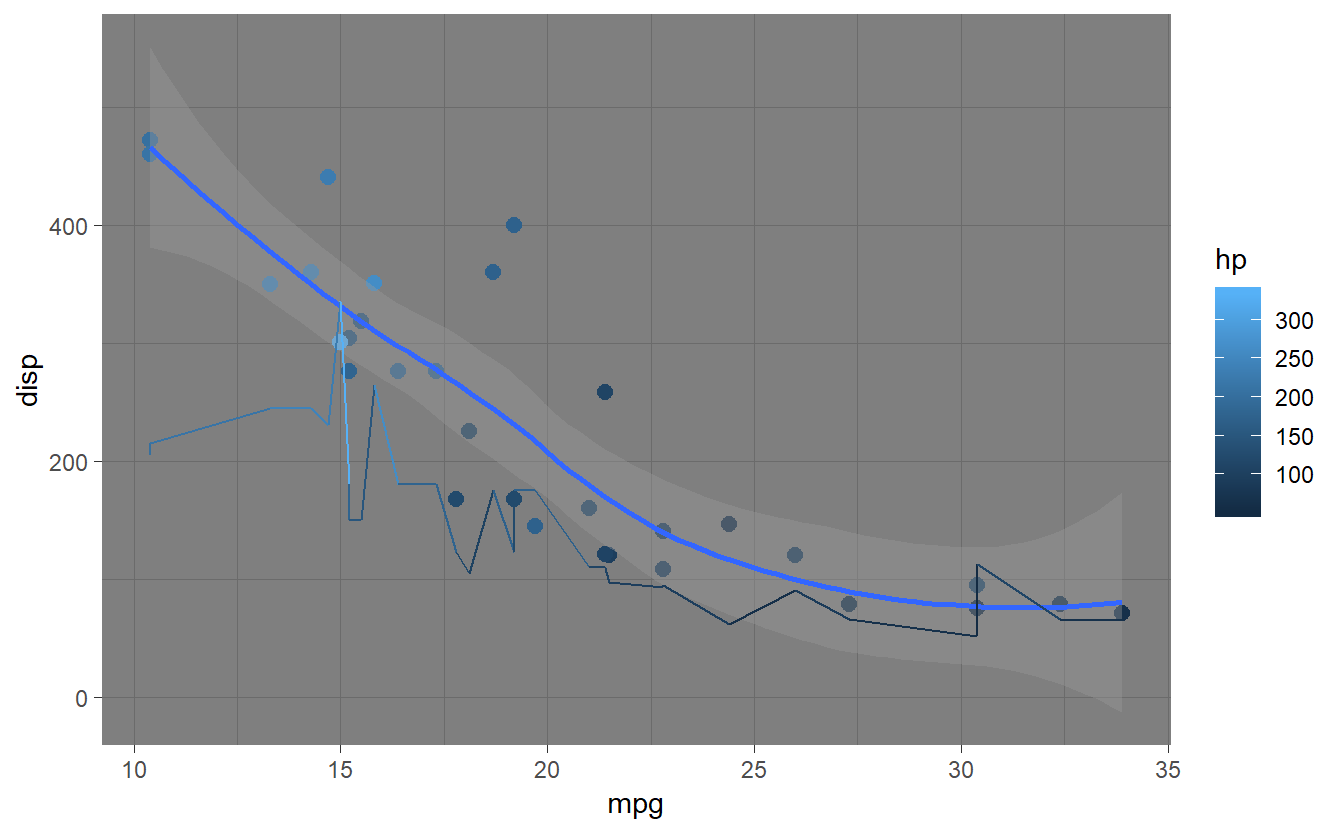
#mesma coisa do anterior, só que sem linhas
grafico + theme(panel.background= element_blank())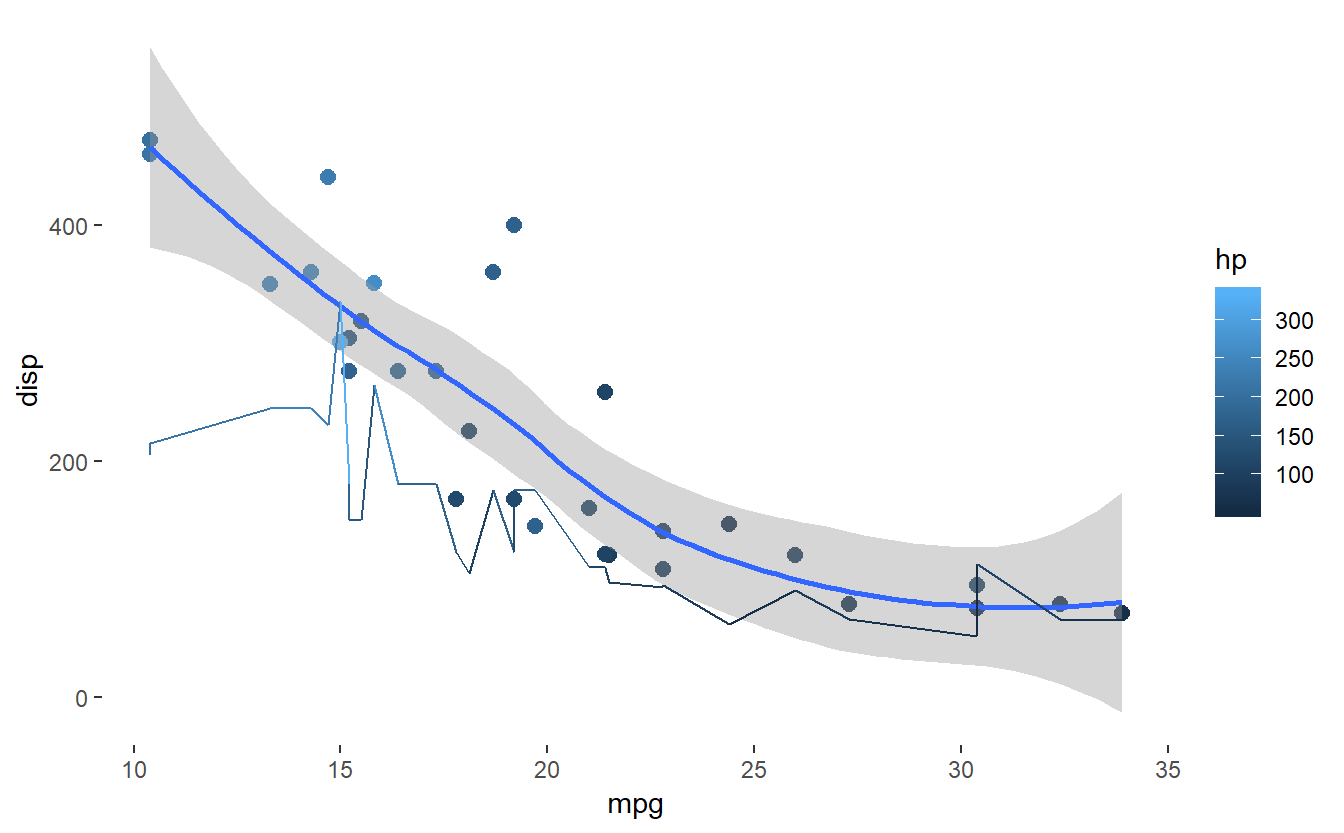
#mesma coisa do anterior, só que mais enxuto ainda
grafico + theme(axis.text = element_blank(),axis.text.x= element_blank(),
axis.text.y= element_blank())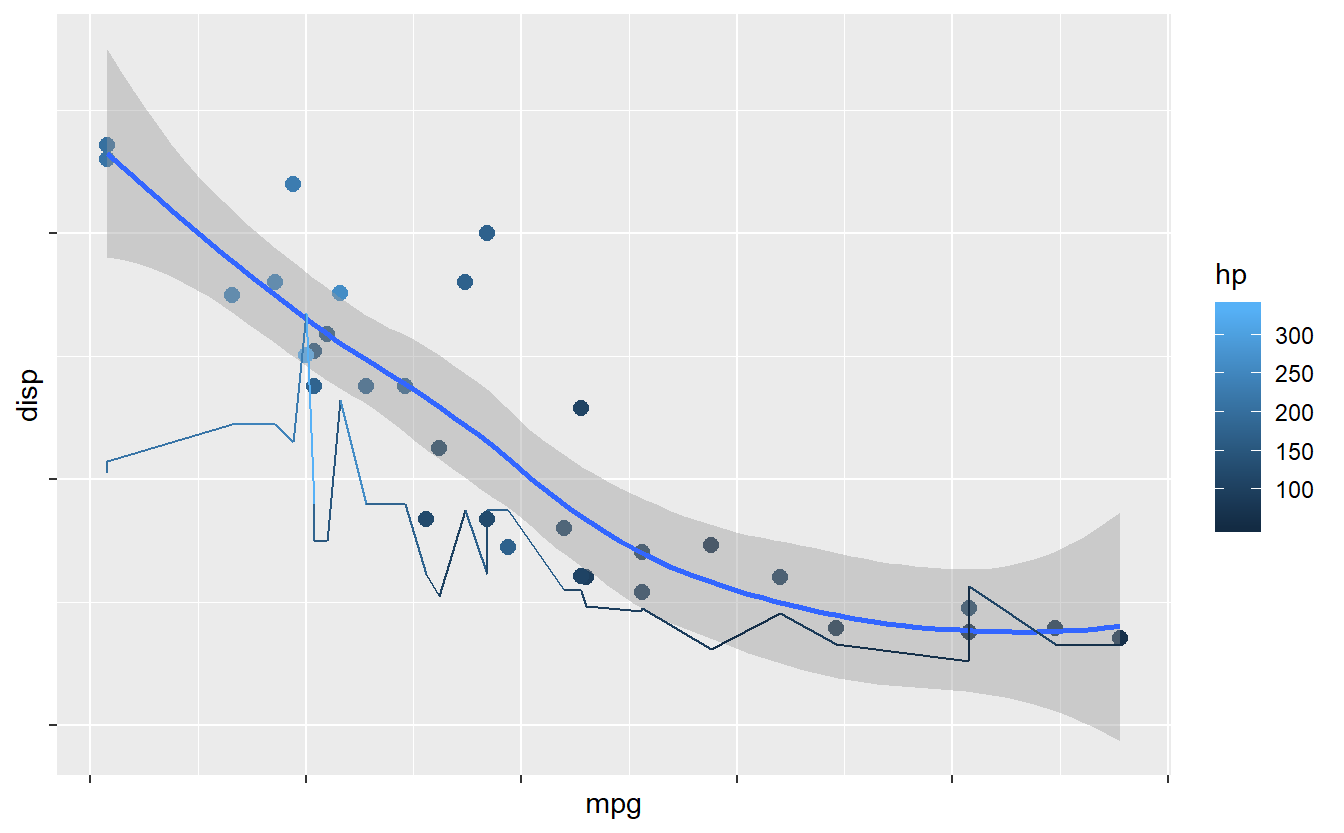
#mesma coisa do anterior, só que com a legenda em outro lugar
grafico + theme(legend.position="top")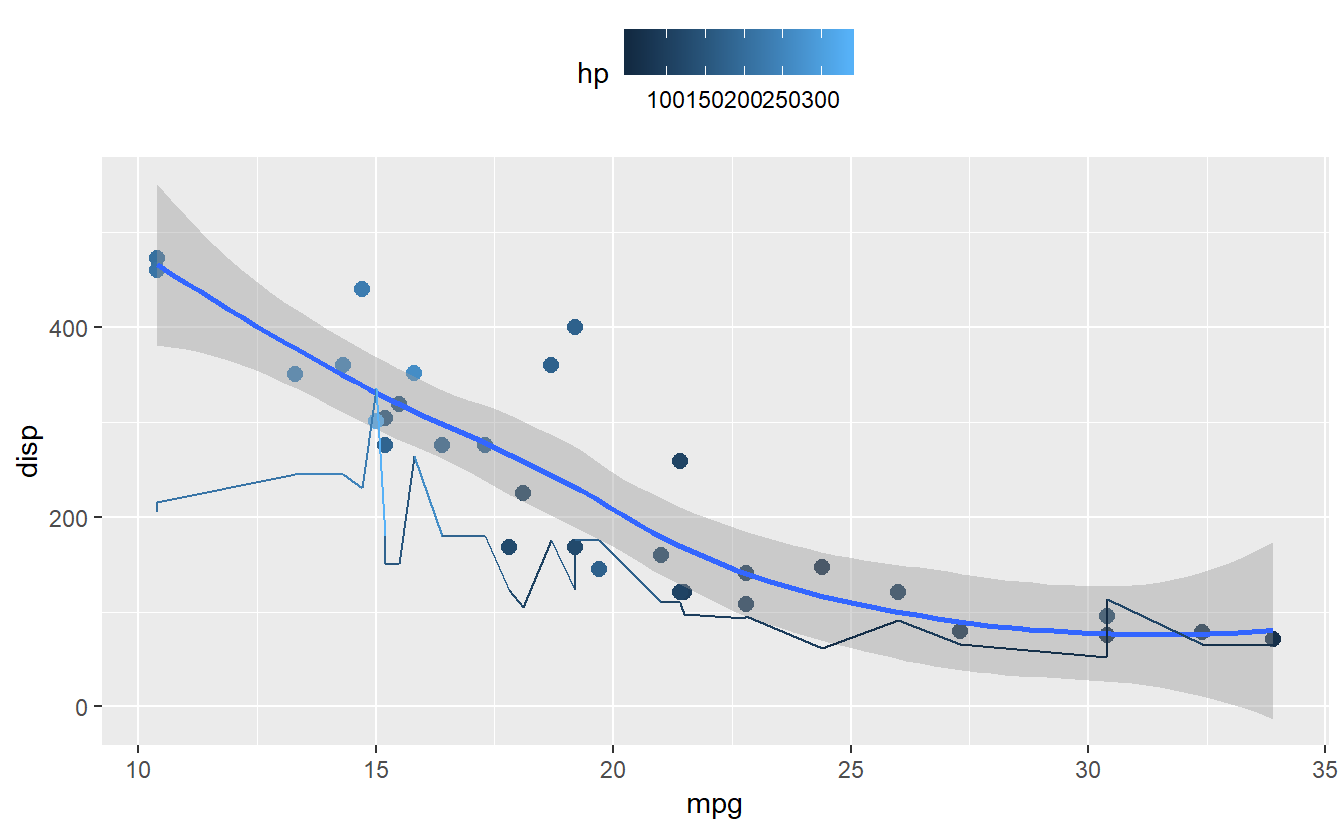
#mesma coisa do anteiror, só que com mudança na escala de cores
grafico + scale_color_gradient(low="yellow",high="red")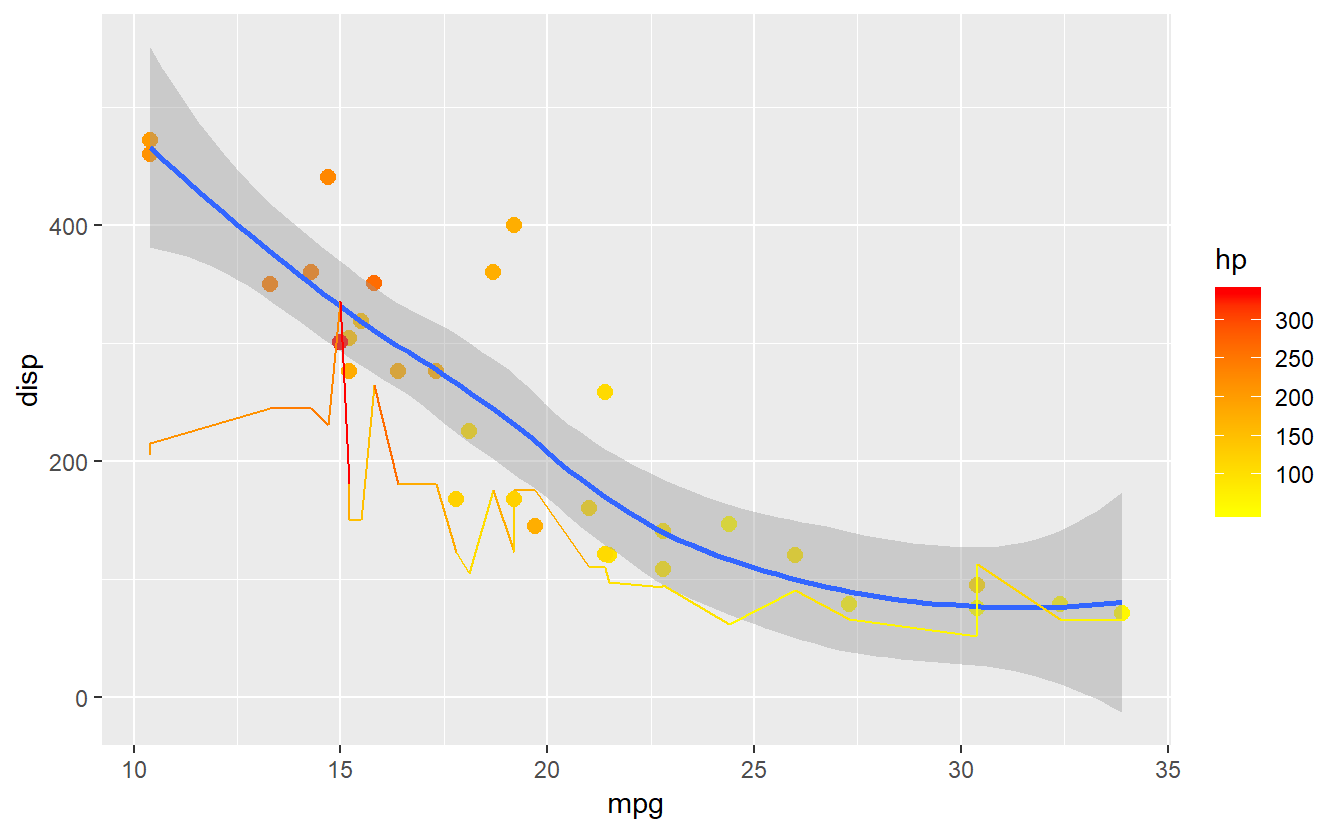
#mesma coisa do anterior, só que com mais granularidade na escala de cores
grafico + scale_color_gradient2(low="yellow",mid="green",high="red")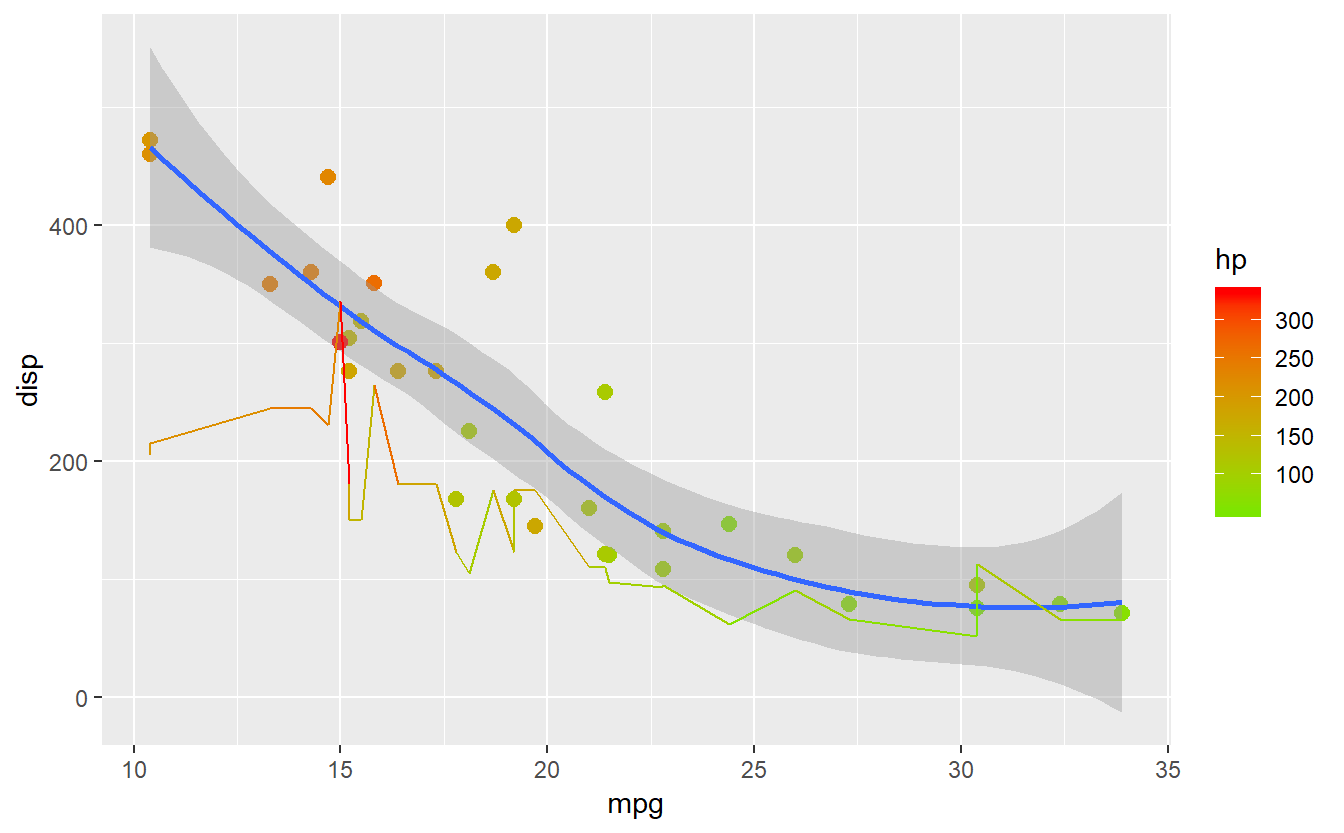
#mesma coisa do anterior, só que com mudança de escala
grafico + scale_color_continuous(name = "cavalo-vapor",
breaks = seq(50,350,75), labels = paste(seq(50,350,75),"hps"))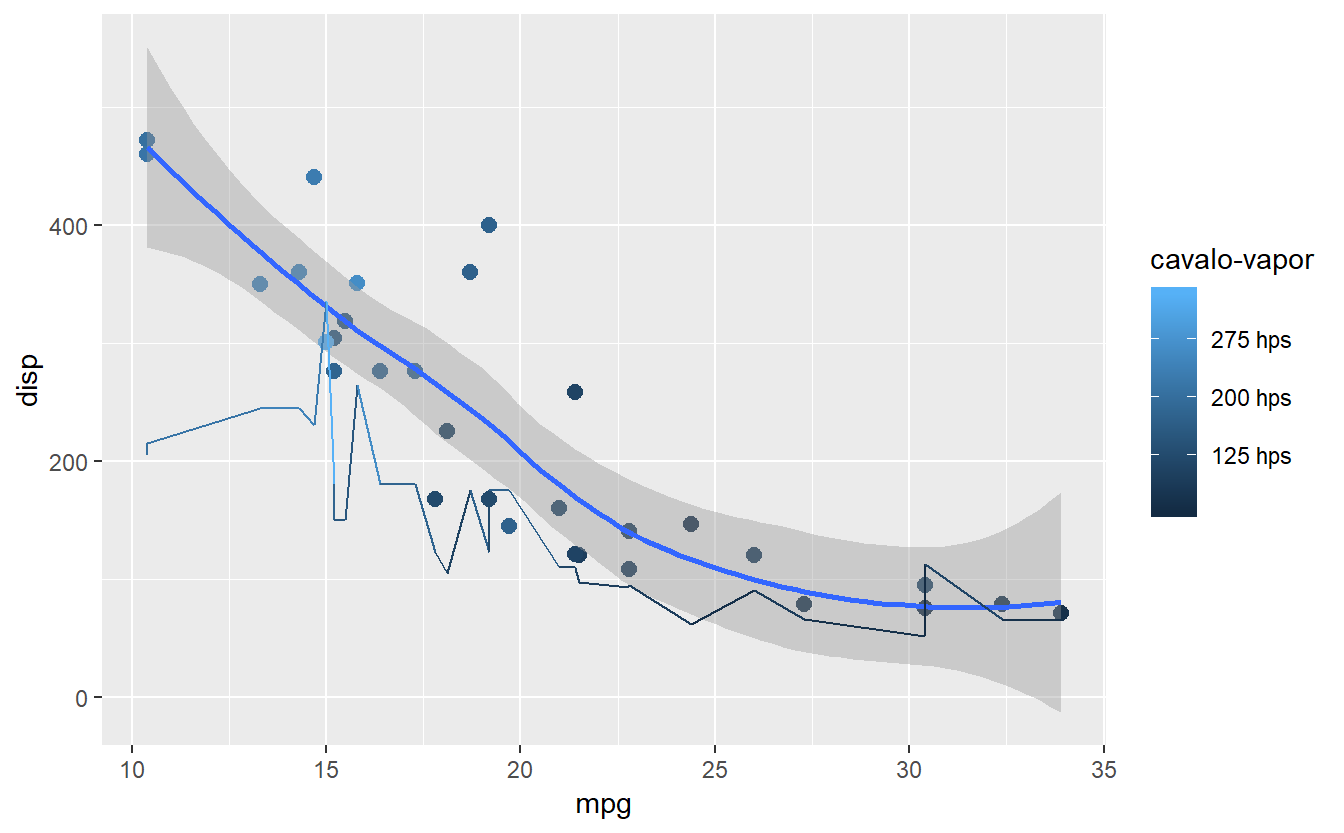
#mesma coisa do anterior, só que com escala de cores diferente
grafico + scale_color_gradient(low = "blue",high = "red") +
scale_color_continuous( breaks = seq(50,350,75))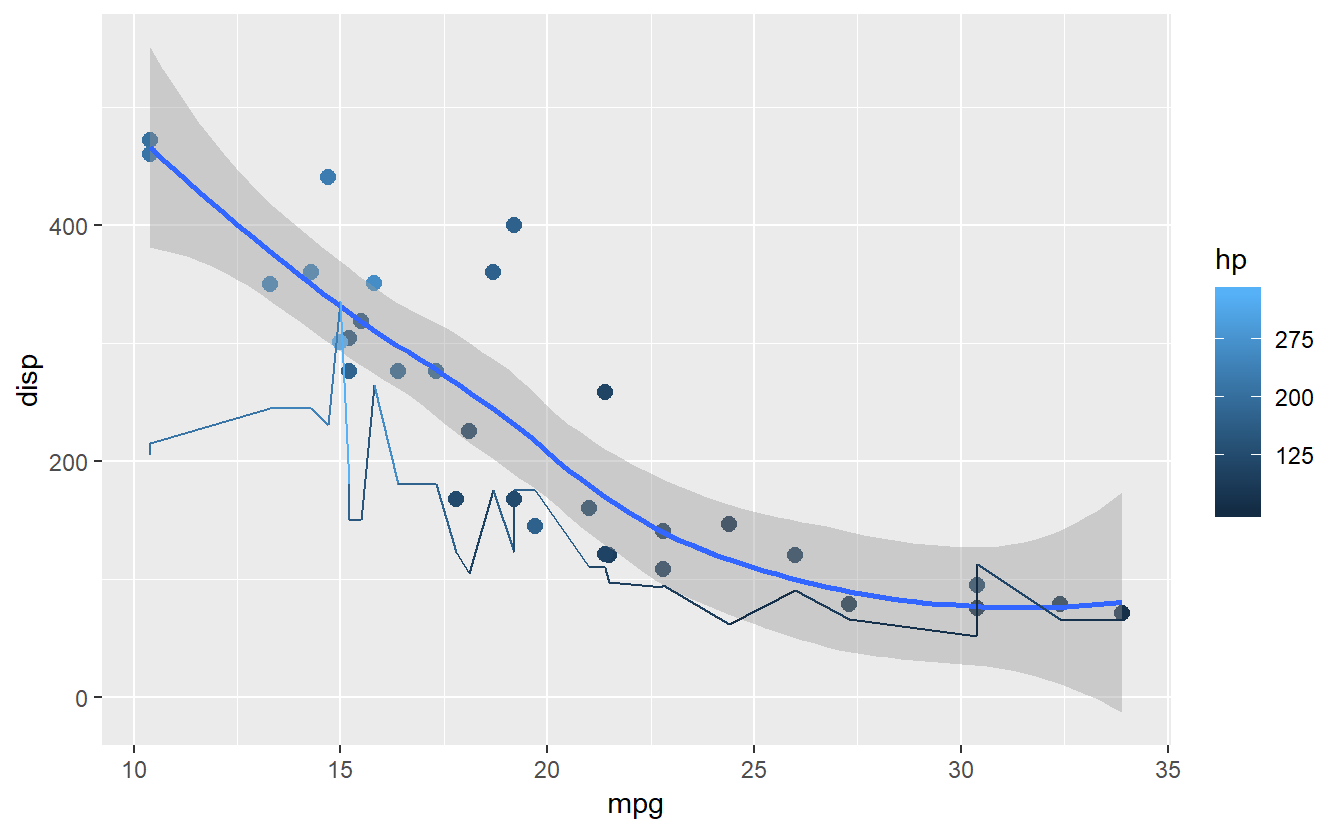
Faceting
Faceting é o recurso de apresentar diversos gráficos em uma única observação. Para a demonstração do próximo faceting, exibiremos o seguinte:
#criando vários gráficos para cada elemento único de carb
ggplot(data=mtcars,aes(x=mpg,y=disp)) + geom_point() + facet_wrap(~carb)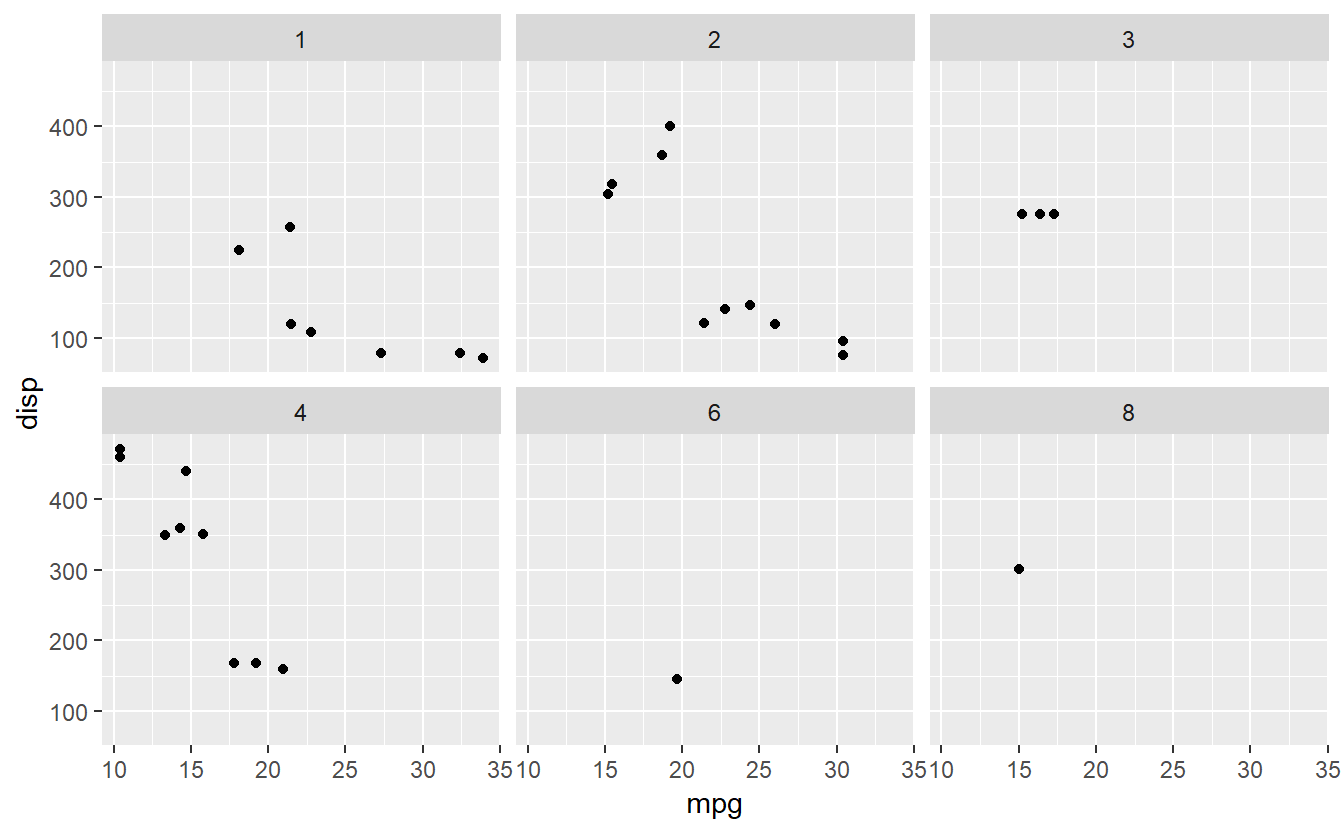
#o mesmo recurso anterior, mas faceting com am e carb, agora (label em ambos)
ggplot(data=mtcars,aes(x=mpg,y=disp)) + geom_point() +
facet_wrap(~carb + am, labeller="label_both")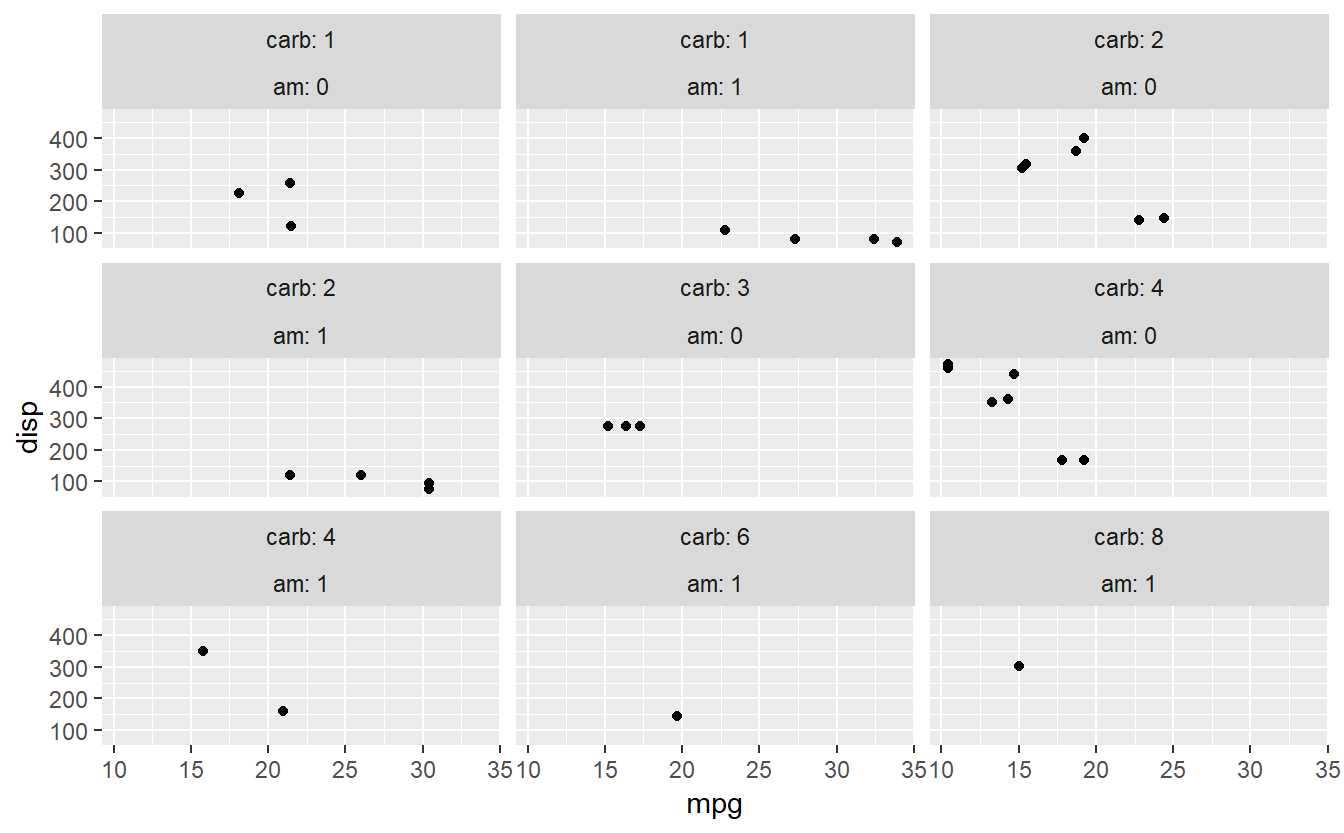
Exemplo de exploração de dados
Criaremos agora um dataset chamado populacao contendo 400 entradas para homens e mulheres, com médias de pesos entre as pessoas:
#carregando a biblioteca plyr
library(plyr)
#criando dataframe com dados
populacao <- data.frame(
sex=factor(rep(c("F", "M"), each=200)),
weight=round(c(rnorm(200, mean=55, sd=5),
rnorm(200, mean=65, sd=5)))
)
#exibição de 20 valores aleatórios
sample_n(populacao,20,replace=FALSE)## sex weight
## 271 M 61
## 255 M 66
## 173 F 59
## 68 F 60
## 257 M 70
## 16 F 53
## 334 M 62
## 324 M 67
## 222 M 71
## 282 M 67
## 40 F 52
## 392 M 63
## 66 F 48
## 291 M 69
## 166 F 45
## 81 F 46
## 288 M 65
## 145 F 53
## 164 F 57
## 195 F 66É importante criar um dataframe, mu, contendo a média de cada uma das populações por sexo, para a criação de uma linha pontilhada no gráfico:
#calculando a média de cada grupo
mu <- ddply(populacao,"sex",summarise,grp.mean=mean(weight))
mu## sex grp.mean
## 1 F 55.265
## 2 M 65.200Criando um gráfico de densidade básico e armazenando em p:
p <- ggplot(populacao, aes(x=weight)) + geom_area(stat = "bin") +
geom_area(aes(y = ..density..), stat = "bin") +
geom_area(stat = "bin", fill = "lightblue")
p + geom_vline(aes(xintercept=mean(weight)),
color="blue", linetype="dashed", size=1)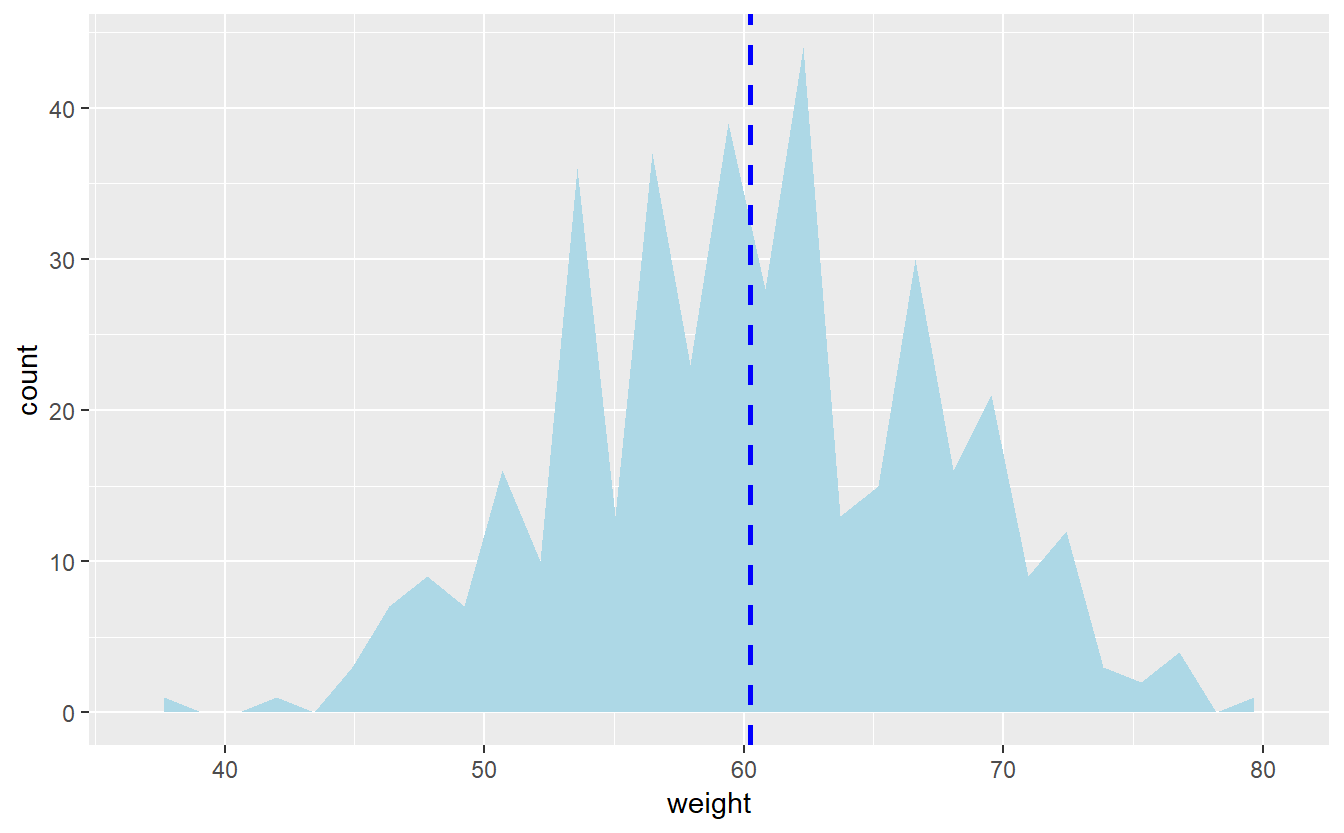
Fazendo variações:
#mudando tipos e cores de linhas
p + geom_area(stat="bin",color="darkblue",fill="lightblue") + geom_vline(aes(xintercept=mean(weight)),
color="blue", linetype="dashed", size=1)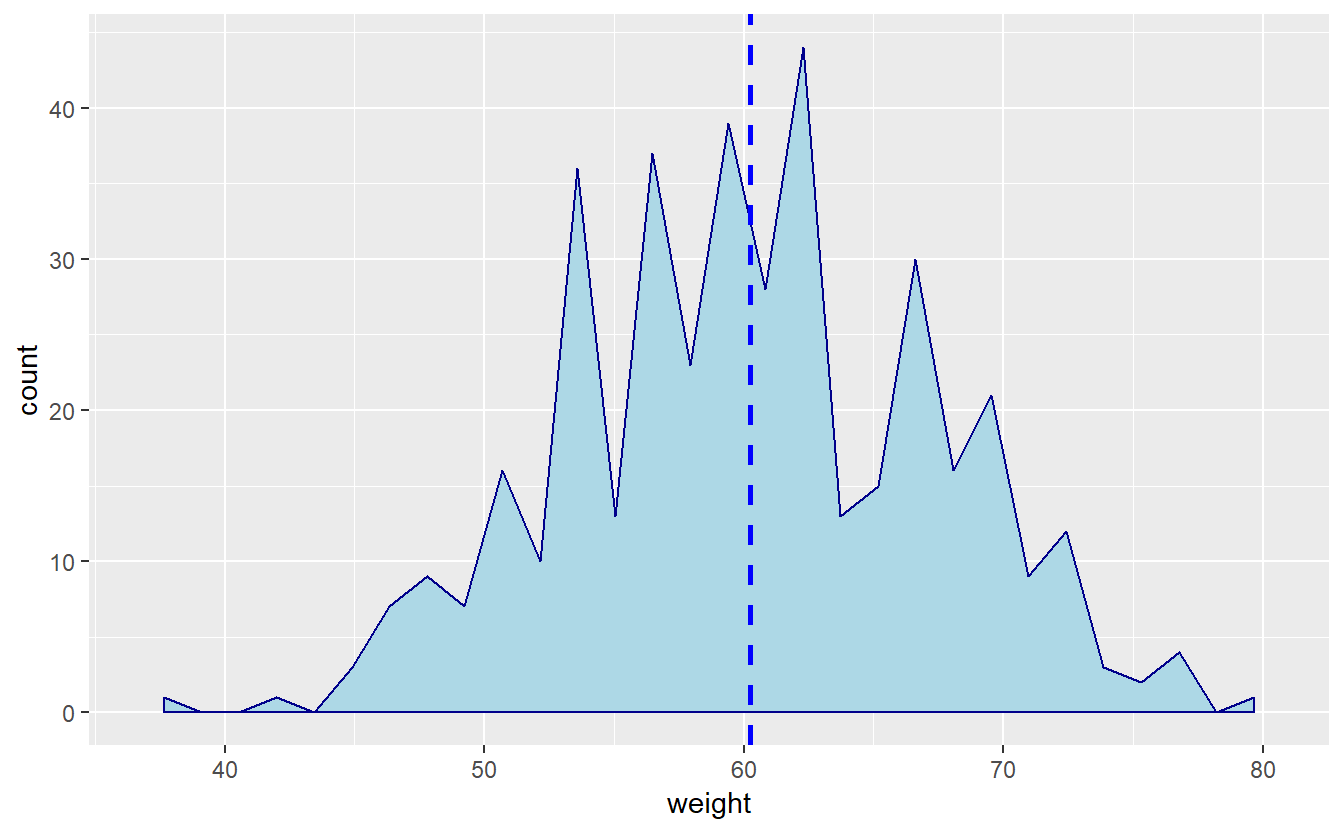
p + geom_area(stat="bin",color="black",fill="lightgrey",linetype="dashed") + geom_vline(aes(xintercept=mean(weight)),
color="blue", linetype="dashed", size=1)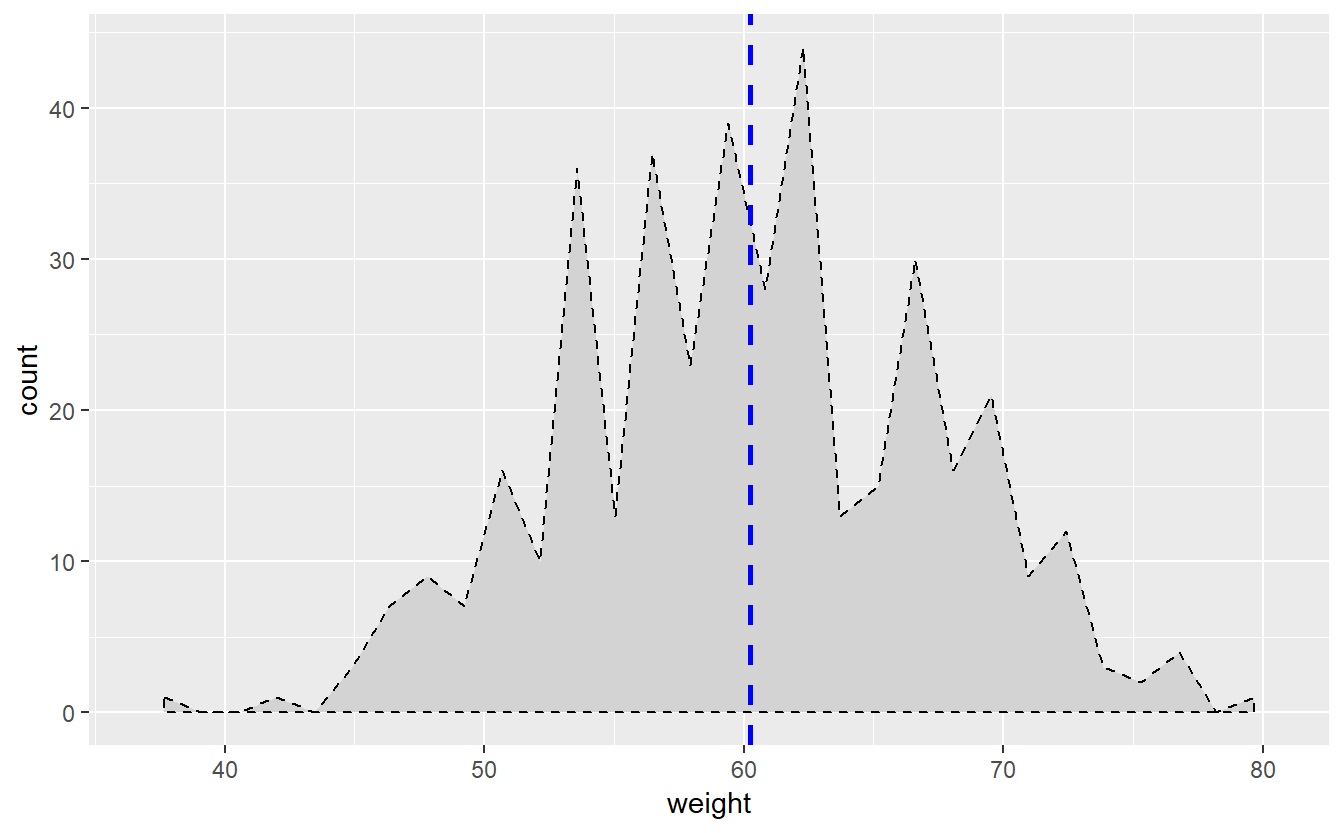
#colorindo os grupos diferentes nos gráficos
p2 <- ggplot(populacao, aes(x=weight, fill=sex)) +
geom_area(stat ="bin", alpha=0.6) +
theme_classic() + geom_vline(data=mu,aes(xintercept=grp.mean,
color=sex),linetype="dashed")#mudando as cores manualmente (três alternativas)
p2 + scale_fill_manual(values=c("#999999","#E69F00"))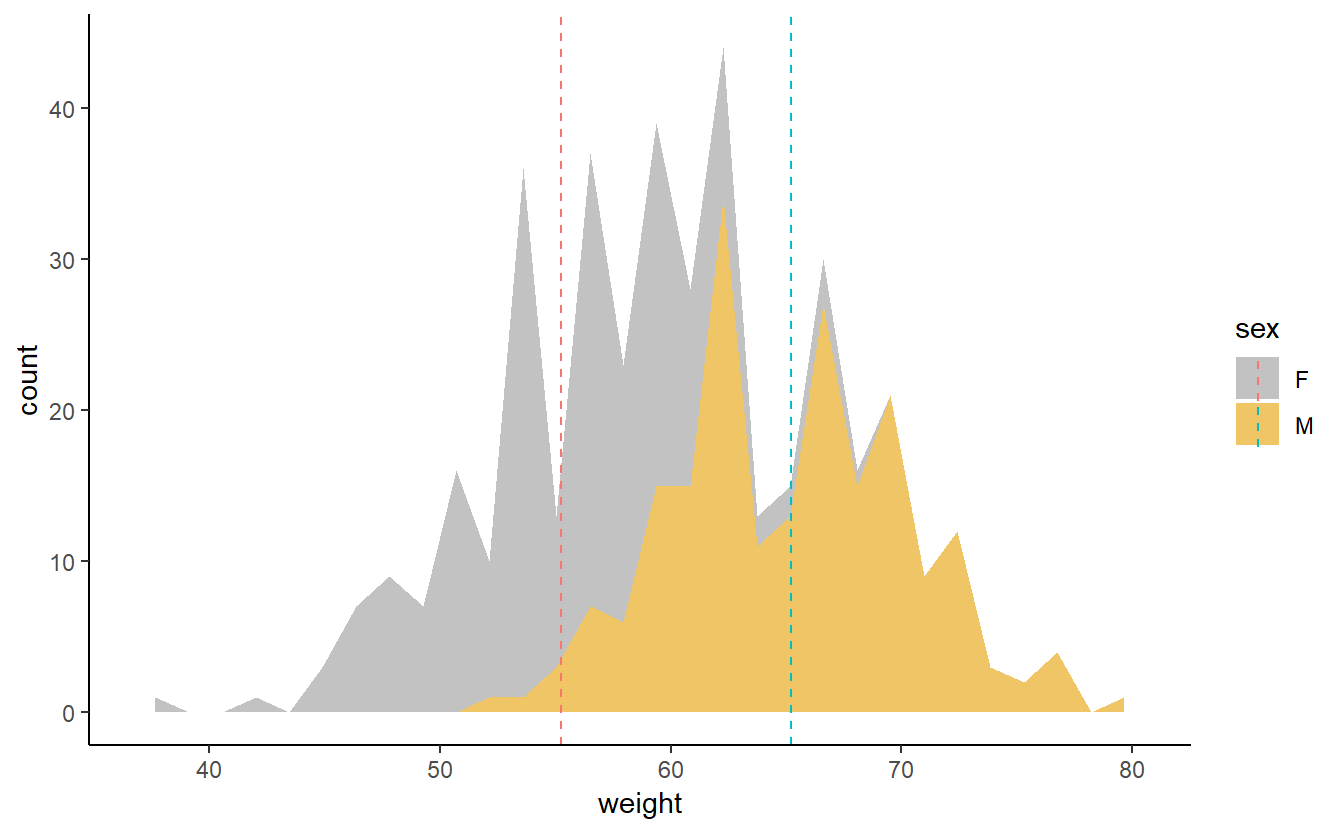
p2 + scale_fill_brewer(palette="Dark2")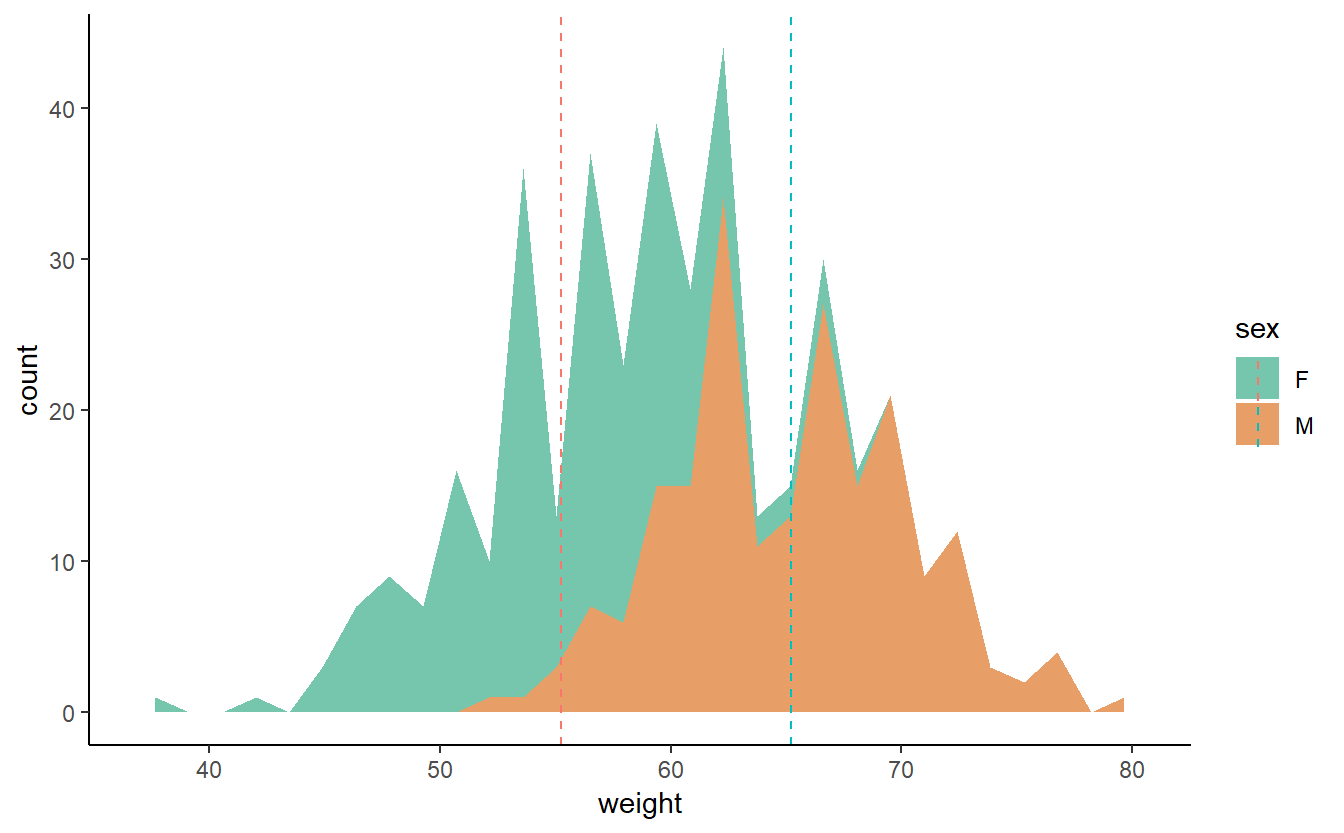
p2 + scale_fill_grey()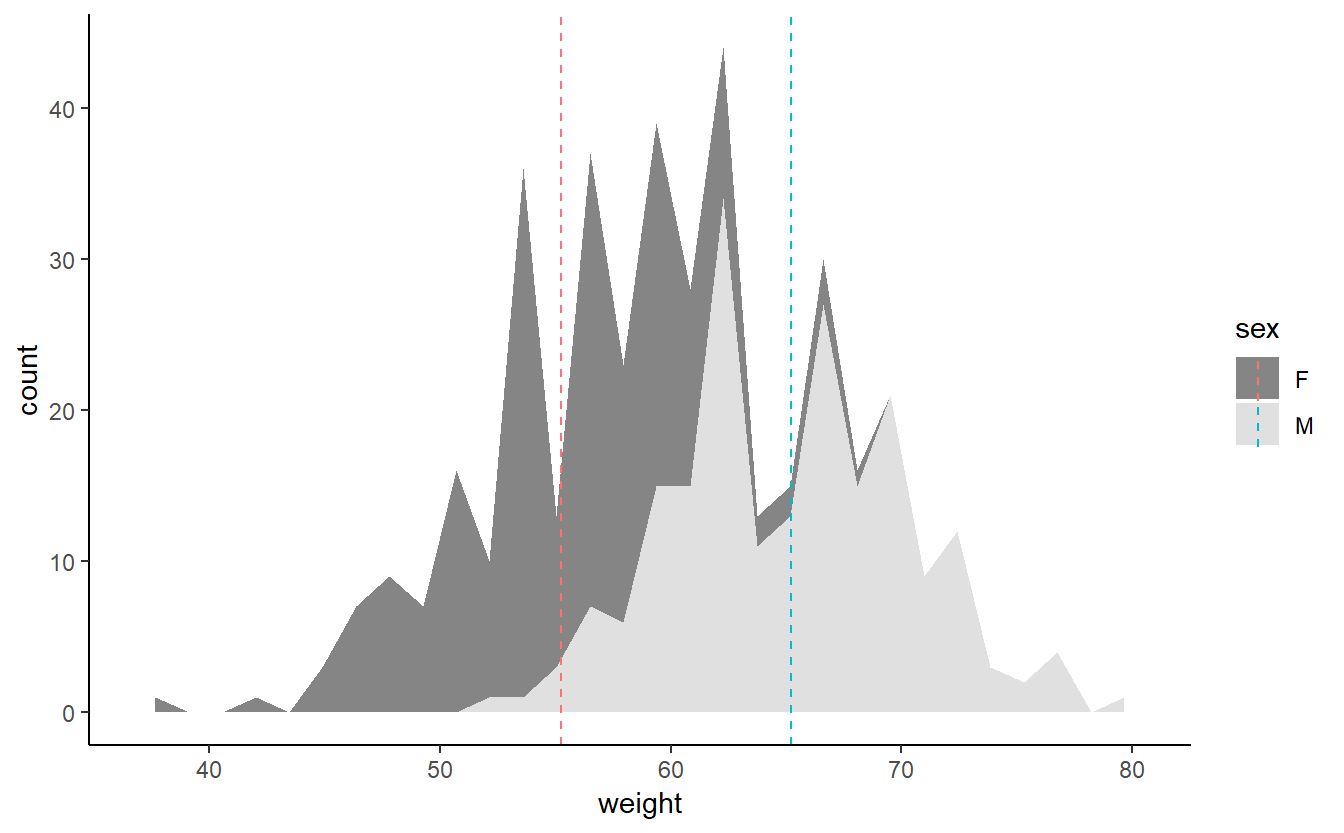
#dividindo por facets
p + facet_grid(sex ~.) + geom_vline(data=mu,aes(xintercept=grp.mean,
color="red",linetype="dashed"))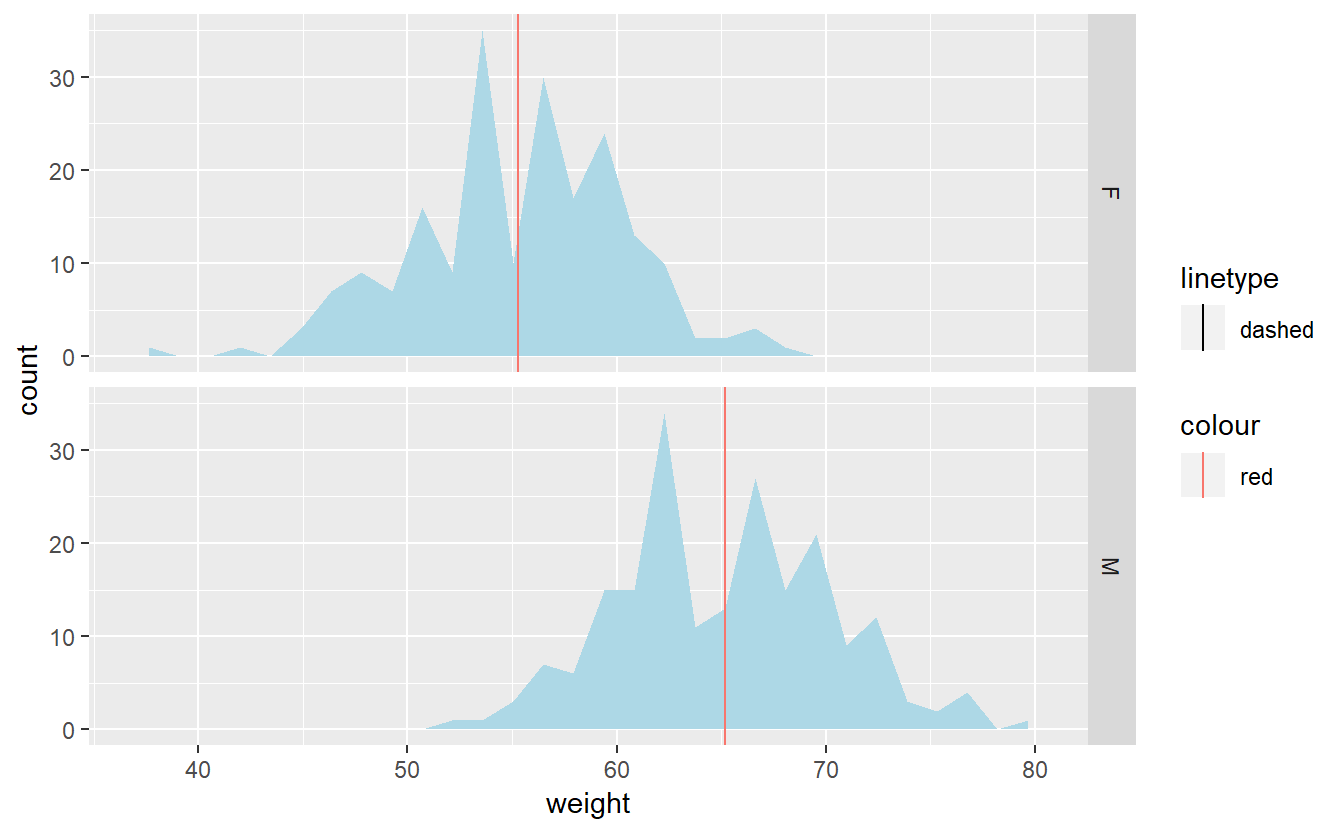
Criaremos um objeto, dat, contendo a curva de densidade dos pesos das pessoas, para plotar a área abaixo de uma certa região da curva:
#curva de densidade dos pesos das pessoas
dat <- with(density(populacao$weight), data.frame(x, y))
#plotando área abaixo da curva (x entre 65 e70)
ggplot(data = dat, mapping = aes(x = x, y = y)) +
geom_line()+
geom_area(mapping = aes(x = ifelse(x>65 & x< 70 , x, 0)), fill = "red") +
xlim(30, 80)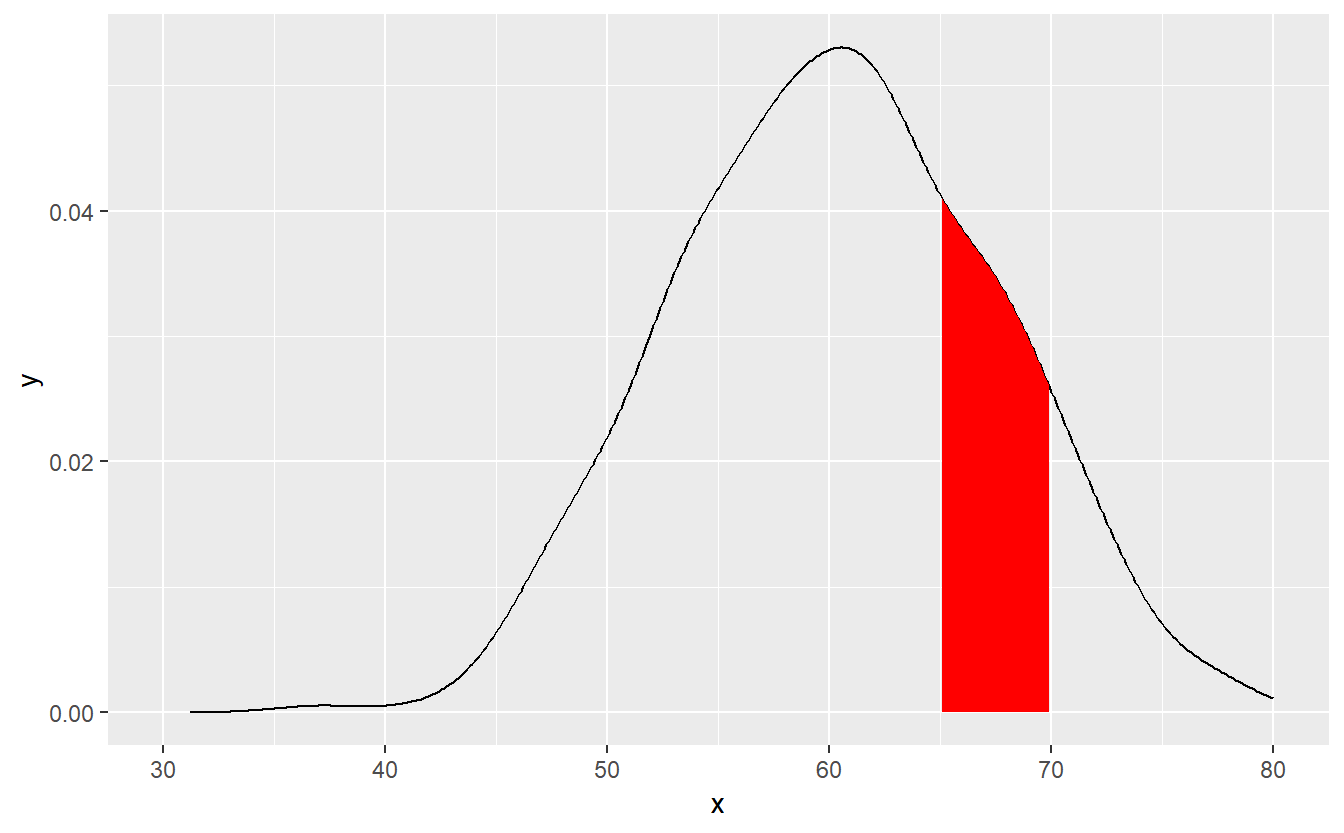
Data frames
Disposições gerais
Data frames são estruturas versáteis e com muitas funcionalidades em R. Possuem bastante semelhança com matrizes, com a diferença de que algumas funções, tanto nativas quanto de pacotes específicos, funcionam unicamente neles. Como exemplo, será criado um data frame de 5 colunas e 100 entradas, através da função nativa data.frame():
#criando um dataframe com valores aleatórios
mydata = data.frame(Q1 = sample(1:6, 100, replace = TRUE),
Q2 = sample(1:6, 100, replace = TRUE),
Q3 = sample(1:6, 100, replace = TRUE),
Q4 = sample(1:6, 100, replace = TRUE),
Age = sample(1:3, 100, replace = TRUE))Distribuindo propositalmente valores faltantes no data frame:
mydata[1,3] <- NA
mydata[6,1] <- NA
mydata[17,4] <- NA
mydata[23,4] <- NA
mydata[38,2] <- NA
mydata[55,3] <- NA
mydata[80,1] <- NAVisualizando um breve resumo sobre o data frame:
##breve resumo estatístico
summary(mydata)## Q1 Q2 Q3 Q4
## Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000
## Median :3.000 Median :4.000 Median :3.000 Median :4.000
## Mean :3.418 Mean :3.687 Mean :3.296 Mean :3.704
## 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:4.000 3rd Qu.:5.000
## Max. :6.000 Max. :6.000 Max. :6.000 Max. :6.000
## NA's :2 NA's :1 NA's :2 NA's :2
## Age
## Min. :1.00
## 1st Qu.:1.00
## Median :2.00
## Mean :1.91
## 3rd Qu.:3.00
## Max. :3.00
## Também é possível visualizar colunas específicas, como a terceira coluna em questão:
summary(mydata$Q3)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 2.000 3.000 3.296 4.000 6.000 2Outra informação possível de ser extraída é a quantidade de colunas e de entradas, caso não se saiba:
##quantidade de entradas num data frame
nrow(mydata)## [1] 100##quantidade de variáveis num data frame
ncol(mydata)## [1] 5Ainda um outro tipo de informação que pode ser inferida do data frame é a sua estrutura de composição, através da função nativa str(). Esta função descreve o tipo de cada uma das variáveis:
str(mydata)## 'data.frame': 100 obs. of 5 variables:
## $ Q1 : int 2 3 4 6 5 NA 5 5 4 4 ...
## $ Q2 : int 6 5 5 1 6 5 3 3 6 5 ...
## $ Q3 : int NA 3 3 2 6 5 4 4 1 6 ...
## $ Q4 : int 2 2 4 4 6 2 6 2 1 1 ...
## $ Age: int 3 2 2 2 2 2 1 1 1 1 ...Também é possível visualizar apenas as primeiras X entradas ou as últimas Y entradas de um data frame através das funções head() e tail():
#primeiras 5 entradas
head(mydata, n=5)## Q1 Q2 Q3 Q4 Age
## 1 2 6 NA 2 3
## 2 3 5 3 2 2
## 3 4 5 3 4 2
## 4 6 1 2 4 2
## 5 5 6 6 6 2#todas menos as 50 primeiras entradas
tail(mydata, n=-50)## Q1 Q2 Q3 Q4 Age
## 51 6 1 4 5 2
## 52 3 5 2 2 1
## 53 5 4 1 3 1
## 54 3 6 3 2 2
## 55 2 2 NA 5 2
## 56 1 4 5 3 2
## 57 6 1 2 6 3
## 58 2 6 2 6 3
## 59 6 5 4 4 2
## 60 5 3 4 4 1
## 61 2 1 5 2 3
## 62 2 4 3 5 1
## 63 2 5 6 1 3
## 64 4 6 5 3 2
## 65 1 6 4 3 2
## 66 3 2 6 6 2
## 67 4 2 5 5 2
## 68 4 1 1 6 3
## 69 3 4 3 1 1
## 70 3 4 1 1 2
## 71 2 1 3 4 1
## 72 3 2 4 3 1
## 73 6 6 2 4 1
## 74 1 6 2 1 1
## 75 4 1 6 4 2
## 76 1 3 3 1 1
## 77 6 5 4 6 3
## 78 6 2 2 1 3
## 79 5 3 1 3 1
## 80 NA 1 6 6 1
## 81 6 2 4 4 2
## 82 2 6 1 6 1
## 83 5 2 1 3 2
## 84 2 2 2 5 2
## 85 6 4 2 3 3
## 86 6 3 2 5 2
## 87 5 4 2 5 2
## 88 1 5 6 6 2
## 89 2 6 3 5 2
## 90 5 1 4 2 1
## 91 6 5 6 5 3
## 92 1 4 2 3 1
## 93 3 1 2 3 3
## 94 2 6 3 4 3
## 95 2 4 1 2 1
## 96 3 2 4 5 3
## 97 4 1 6 5 3
## 98 2 2 4 5 3
## 99 1 1 1 4 1
## 100 1 4 4 4 3Valores aleatórios
Há diversas maneiras de se gerar e se selecionar valores aleatórios em um data frame. Utilizando a biblioteca dplyr, um analista ou um cientista de dados pode fazer uso de funções que aceleram esse processo, pois as funções nativas do R executariam a mesma tarefa com mais passos. Carregando-se a biblioteca:
library(dplyr)Selecionando valores aleatoriamente com a função sample_n() do pacote dplyr:
#selecionando 11 entradas aleatoriamente
sample_n(mydata,11)## Q1 Q2 Q3 Q4 Age
## 74 1 6 2 1 1
## 94 2 6 3 4 3
## 3 4 5 3 4 2
## 75 4 1 6 4 2
## 1 2 6 NA 2 3
## 90 5 1 4 2 1
## 60 5 3 4 4 1
## 54 3 6 3 2 2
## 45 3 2 3 4 1
## 57 6 1 2 6 3
## 61 2 1 5 2 3Também é possível selecionar aleatoriamente através de percentuais, com a função sample_frac():
#selecionando 43% das entradas aleatoriamente
sample_frac(mydata, 0.43)## Q1 Q2 Q3 Q4 Age
## 5 5 6 6 6 2
## 32 3 4 3 5 3
## 20 3 5 1 5 1
## 24 5 6 4 5 3
## 87 5 4 2 5 2
## 85 6 4 2 3 3
## 61 2 1 5 2 3
## 3 4 5 3 4 2
## 25 3 6 6 6 3
## 11 6 1 4 4 1
## 68 4 1 1 6 3
## 76 1 3 3 1 1
## 84 2 2 2 5 2
## 16 1 1 2 3 2
## 39 2 6 4 4 1
## 99 1 1 1 4 1
## 63 2 5 6 1 3
## 10 4 5 6 1 1
## 43 2 3 2 1 3
## 71 2 1 3 4 1
## 37 2 5 3 5 3
## 35 6 1 5 6 1
## 66 3 2 6 6 2
## 60 5 3 4 4 1
## 78 6 2 2 1 3
## 56 1 4 5 3 2
## 41 5 2 4 6 3
## 8 5 3 4 2 1
## 81 6 2 4 4 2
## 58 2 6 2 6 3
## 15 6 5 2 3 3
## 2 3 5 3 2 2
## 54 3 6 3 2 2
## 74 1 6 2 1 1
## 89 2 6 3 5 2
## 47 3 5 5 2 3
## 88 1 5 6 6 2
## 17 6 5 1 NA 3
## 19 5 4 6 3 3
## 1 2 6 NA 2 3
## 18 4 3 1 1 1
## 75 4 1 6 4 2
## 42 5 5 3 6 1Valores não registrados e substituídos
Por alguma razão, algumas entradas deixam de preencher valores para algumas das variáveis/colunas, seja por falta de atenção, ruído, ausência de valores em si, intenção etc. Com algumas funções no R, é possível ter uma visão sobre as condições de um data frame, em relação aos valores não registrados:
#número de valores ausentes na coluna
colSums(is.na(mydata))## Q1 Q2 Q3 Q4 Age
## 2 1 2 2 0#valores faltantes por entrada
rowSums(is.na(mydata))## [1] 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
## [36] 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [71] 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0#número de valores ausentes em uma variável específica (nesse caso, na variável Q1)
sum(is.na(mydata$Q1))## [1] 2Há também a possibilidade de se substituir valores em entradas. Isso pode ser de interesse do analista ou do cientista de dados quando houver a necessidade de se preencher valores não registrados ou mesmo modificar a representação de um tipo de registro por algo mais significativo (por exemplo, em uma coluna que registre pronomes de tratamento, “senhor” e “Sr.” representam, em algumas análises, a mesma informação. Neste caso, substituir ambos pela forma “SENHOR” seria ideal para a contagem padronizada de quantas entradas do determinado data frame utilizam este tipo de pronome de tratamento).
#substituindo um valor específico do data frame (onde houver 1 ou 2 em Q1, vira 6)
mydata$Q1[mydata$Q1==1|mydata$Q1==2] <- 6Também há a possibilidade de exclusão de uma variável do data frame:
#deletando uma coluna de um data frame (a terceira)
mydata$Q3 <- NULL
head(mydata)## Q1 Q2 Q4 Age
## 1 6 6 2 3
## 2 3 5 2 2
## 3 4 5 4 2
## 4 6 1 4 2
## 5 5 6 6 2
## 6 NA 5 2 2Seleção
Filtrar e selecionar são duas atividades importantes para a análise dos dados presentes em um data frame. O resultado final pode ser apresentado apenas em console ou também guardado em um outro data frame.
#selecionar as oito primeiras entradas (todas as colunas)
selecao <- mydata[1:8,]
selecao## Q1 Q2 Q4 Age
## 1 6 6 2 3
## 2 3 5 2 2
## 3 4 5 4 2
## 4 6 1 4 2
## 5 5 6 6 2
## 6 NA 5 2 2
## 7 5 3 6 1
## 8 5 3 2 1Também é possível fazer este procedimento utilizando-se de regras condicionais:
#selecionar as entradas onde Q1 seja maior que 2
novo <- subset(mydata,Q1>2)
summary(novo)## Q1 Q2 Q4 Age
## Min. :3.00 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:4.00 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.000
## Median :6.00 Median :4.000 Median :4.000 Median :2.000
## Mean :4.98 Mean :3.701 Mean :3.698 Mean :1.918
## 3rd Qu.:6.00 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:3.000
## Max. :6.00 Max. :6.000 Max. :6.000 Max. :3.000
## NA's :1 NA's :2Esta seleção condicional pode ser simplificada, como o exemplo anterior, ou mesmo ter diversos requisitos:
#seleção com AND de entradas (com OR é a mesma ideia)
restrito <- subset(mydata,Age >=3 & Q1 > 2)
summary(restrito)## Q1 Q2 Q4 Age
## Min. :3.000 Min. :1.000 Min. :1.000 Min. :3
## 1st Qu.:4.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:3
## Median :6.000 Median :4.000 Median :4.000 Median :3
## Mean :5.034 Mean :3.724 Mean :3.786 Mean :3
## 3rd Qu.:6.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:3
## Max. :6.000 Max. :6.000 Max. :6.000 Max. :3
## NA's :1Por fim, valores faltantes também podem ser filtrados e deixados de fora, levando-se em consideração todo o data frame ou apenas uma das colunas:
#salvando apenas resultados não vazios (baseando-se em Q4)
significativo <- subset(mydata,!is.na(Q4))
summary(significativo)## Q1 Q2 Q4 Age
## Min. :3.00 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:4.00 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.000
## Median :6.00 Median :4.000 Median :4.000 Median :2.000
## Mean :4.99 Mean :3.701 Mean :3.704 Mean :1.908
## 3rd Qu.:6.00 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:3.000
## Max. :6.00 Max. :6.000 Max. :6.000 Max. :3.000
## NA's :2 NA's :1#criando dataset sem valores faltantes a partir de um já existente
mydata1 <- na.omit(mydata)
summary(mydata1)## Q1 Q2 Q4 Age
## Min. :3.000 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:4.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.000
## Median :6.000 Median :4.000 Median :4.000 Median :2.000
## Mean :4.979 Mean :3.716 Mean :3.695 Mean :1.916
## 3rd Qu.:6.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:3.000
## Max. :6.000 Max. :6.000 Max. :6.000 Max. :3.000Ordenação e junção
Além de selecionar e observar, é possível operar modificando o data frame por intermédio de reordenação da posição das entradas e da junção de dois ou mais data frames. Como primeiro exemplo, o data frame mydata será reordenado levando-se em consideração uma de suas variáveis:
#reordenando e salvando em outro data frame, a partir da variável Q1
ordered <- mydata[order(mydata$Q1),]
head(ordered)## Q1 Q2 Q4 Age
## 2 3 5 2 2
## 20 3 5 5 1
## 23 3 1 NA 1
## 25 3 6 6 3
## 28 3 4 2 2
## 29 3 3 2 3Essa reordenação também pode ser feita levando-se em consideração mais de uma variável ao mesmo tempo:
#reordenação do data frame ascendente por age e descendente por Q4
ordered2 <- mydata[order(mydata$Age,-mydata$Q4),]
head(ordered2)## Q1 Q2 Q4 Age
## 7 5 3 6 1
## 35 6 1 6 1
## 42 5 5 6 1
## 80 NA 1 6 1
## 82 6 6 6 1
## 12 4 6 5 1A junção pode ocorrer de duas formas: por uma variável específica (logo, os data frames são postos um acima do outro) ou lado a lado. No primeiro caso:
#unindo dois datasets por uma chave primária Q4
mydatatotal <- merge(mydata1,mydata,by=c("Q4"))
summary(mydatatotal)## Q4 Q1.x Q2.x Age.x
## Min. :1.000 Min. :3.000 Min. :1.000 Min. :1.000
## 1st Qu.:3.000 1st Qu.:4.000 1st Qu.:2.000 1st Qu.:1.000
## Median :4.000 Median :6.000 Median :4.000 Median :2.000
## Mean :3.902 Mean :5.006 Mean :3.689 Mean :1.915
## 3rd Qu.:5.000 3rd Qu.:6.000 3rd Qu.:5.000 3rd Qu.:3.000
## Max. :6.000 Max. :6.000 Max. :6.000 Max. :3.000
##
## Q1.y Q2.y Age.y
## Min. :3.000 Min. :1.000 Min. :1.00
## 1st Qu.:4.000 1st Qu.:2.000 1st Qu.:1.00
## Median :6.000 Median :4.000 Median :2.00
## Mean :5.017 Mean :3.676 Mean :1.91
## 3rd Qu.:6.000 3rd Qu.:5.000 3rd Qu.:3.00
## Max. :6.000 Max. :6.000 Max. :3.00
## NA's :25 NA's :17#unindo dois data frames um abaixo do outro, sem chave primária
longo <- rbind(mydata,ordered)
summary(longo)## Q1 Q2 Q4 Age
## Min. :3.00 Min. :1.000 Min. :1.000 Min. :1.00
## 1st Qu.:4.00 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.00
## Median :6.00 Median :4.000 Median :4.000 Median :2.00
## Mean :4.98 Mean :3.687 Mean :3.704 Mean :1.91
## 3rd Qu.:6.00 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:3.00
## Max. :6.00 Max. :6.000 Max. :6.000 Max. :3.00
## NA's :4 NA's :2 NA's :4E no segundo caso:
#unindo dois datasets lado a lado
amplo <- cbind(mydata1,mydata1)
head(amplo)## Q1 Q2 Q4 Age Q1 Q2 Q4 Age
## 1 6 6 2 3 6 6 2 3
## 2 3 5 2 2 3 5 2 2
## 3 4 5 4 2 4 5 4 2
## 4 6 1 4 2 6 1 4 2
## 5 5 6 6 2 5 6 6 2
## 7 5 3 6 1 5 3 6 1